设计模式一文总结
Software-Design Pattern
04/12/2021
以下大部分内容截取自深入设计模式,整理到了一文,方便查阅
定义
定义
设计模式是什么
设计模式是软件设计中常见问题的典型解决方案。 它们就像能根据需求进行调整的预制蓝图, 可用于解决代码中反复出现的设计问题。
设计模式与方法或库的使用方式不同, 你很难直接在自己的程序中套用某个设计模式。 模式并不是一段特定的代码, 而是解决特定问题的一般性概念。 你可以根据模式来实现符合自己程序实际所需的解决方案。
人们常常会混淆模式和算法, 因为两者在概念上都是已知特定问题的典型解决方案。 但算法总是明确定义达成特定目标所需的一系列步骤, 而模式则是对解决方案的更高层次描述。 同一模式在两个不同程序中的实现代码可能会不一样。
算法更像是菜谱: 提供达成目标的明确步骤。 而模式更像是蓝图: 你可以看到最终的结果和模式的功能, 但需要自己确定实现步骤。
模式包含哪些内容?
大部分模式都有正规的描述方式, 以便在不同情况下使用。 模式的描述通常会包括以下部分:
- 意图部分简单描述问题和解决方案。
- 动机部分将进一步解释问题并说明模式会如何提供解决方案。
- 结构部分展示模式的每个部分和它们之间的关系。
- 在不同语言中的实现提供流行编程语言的代码, 让读者更好地理解模式背后的思想。 部分模式介绍中还列出其他的一些实用细节, 例如模式的适用性、 实现步骤以及与其他模式的关系。
设计模式分类
不同设计模式的复杂程度、 细节层次以及在整个系统中的应用范围等方面各不相同。 我喜欢将其类比于道路的建造: 如果你希望让十字路口更加安全, 那么可以安装一些交通信号灯, 或者修建包含行人地下通道在内的多层互通式立交桥。
最基础的、 底层的模式通常被称为惯用技巧。 这类模式一般只能在一种编程语言中使用。
最通用的、 高层的模式是构架模式。 开发者可以在任何编程语言中使用这类模式。 与其他模式不同, 它们可用于整个应用程序的架构设计。
此外, 所有模式可以根据其意图或目的来分类。 本书覆盖了三种主要的模式类别:
创建型模式提供创建对象的机制, 增加已有代码的灵活性和可复用性。
结构型模式介绍如何将对象和类组装成较大的结构, 并同时保持结构的灵活和高效。
行为模式负责对象间的高效沟通和职责委派。
设计模式目录
- 创建型模式
- 结构型模式
- 行为模式
1.1 工厂方法模式
- 问题
对于具有相同方法的不同实现,在不同实现类中,大部分代码都与基类相同,只有少数方法不同
在这种情形下,可以考虑采用工场模式
- 方案、架构
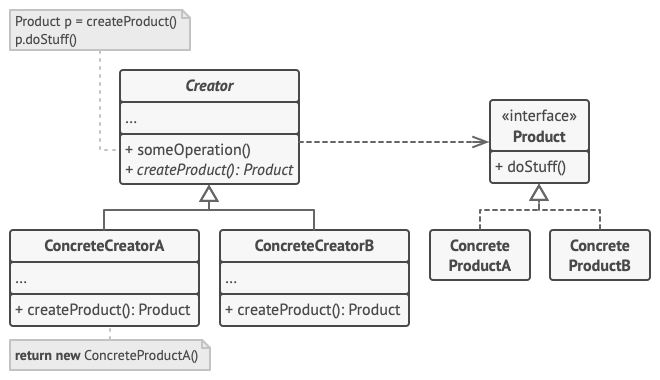
以下示例演示了如何使用工厂方法开发跨平台 UI (用户界面) 组件, 并同时避免客户代码与具体 UI 类之间的耦合。
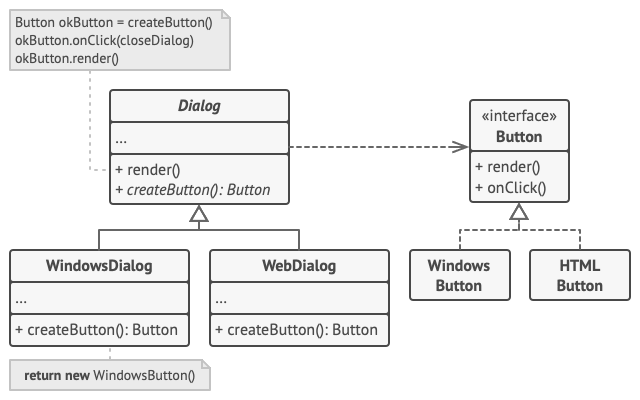
- 适用场景
当你在编写代码的过程中, 如果无法预知对象确切类别及其依赖关系时, 可使用工厂方法。
工厂方法将创建产品的代码与实际使用产品的代码分离, 从而能在不影响其他代码的情况下扩展产品创建部分代码。
例如, 如果需要向应用中添加一种新产品, 你只需要开发新的创建者子类, 然后重写其工厂方法即可。
如果你希望用户能扩展你软件库或框架的内部组件, 可使用工厂方法。
继承可能是扩展软件库或框架默认行为的最简单方法。 但是当你使用子类替代标准组件时, 框架如何辨识出该子类?
解决方案是将各框架中构造组件的代码集中到单个工厂方法中, 并在继承该组件之外允许任何人对该方法进行重写。
让我们看看具体是如何实现的。 假设你使用开源 UI 框架编写自己的应用。 你希望在应用中使用圆形按钮, 但是原框架仅支持矩形按钮。 你可以使用 圆形按钮 RoundButton 子类来继承标准的 按钮 Button 类。 但是, 你需要告诉 UI 框架 UIFramework 类使用新的子类按钮代替默认按钮。
为了实现这个功能, 你可以根据基础框架类开发子类 圆形按钮 UIUIWithRoundButtons , 并且重写其 createButton 创建按钮方法。 基类中的该方法返回 按钮对象, 而你开发的子类返回 圆形按钮对象。 现在, 你就可以使用 圆形按钮 UI 类代替 UI 框架类。 就是这么简单!
如果你希望复用现有对象来节省系统资源, 而不是每次都重新创建对象, 可使用工厂方法。
在处理大型资源密集型对象 (比如数据库连接、 文件系统和网络资源) 时, 你会经常碰到这种资源需求。
让我们思考复用现有对象的方法:
首先, 你需要创建存储空间来存放所有已经创建的对象。 当他人请求一个对象时, 程序将在对象池中搜索可用对象。 …然后将其返回给客户端代码。 如果没有可用对象, 程序则创建一个新对象 (并将其添加到对象池中)。 这些代码可不少! 而且它们必须位于同一处, 这样才能确保重复代码不会污染程序。
可能最显而易见, 也是最方便的方式, 就是将这些代码放置在我们试图重用的对象类的构造函数中。 但是从定义上来讲, 构造函数始终返回的是新对象, 其无法返回现有实例。
因此, 你需要有一个既能够创建新对象, 又可以重用现有对象的普通方法。 这听上去和工厂方法非常相像。
- 优缺点
优点
- 你可以避免创建者和具体产品之间的紧密耦合。
- 单一职责原则。 你可以将产品创建代码放在程序的单一位置, 从而使得代码更容易维护。
- 开闭原则。 无需更改现有客户端代码, 你就可以在程序中引入新的产品类型。
缺点
应用工厂方法模式需要引入许多新的子类, 代码可能会因此变得更复杂。 最好的情况是将该模式引入创建者类的现有层次结构中。
- 与其他模式的关系
在许多设计工作的初期都会使用工厂方法模式 (较为简单, 而且可以更方便地通过子类进行定制), 随后演化为使用抽象工厂模式、 原型模式或生成器模式 (更灵活但更加复杂)。
抽象工厂模式通常基于一组工厂方法, 但你也可以使用原型模式来生成这些类的方法。
你可以同时使用工厂方法和迭代器模式来让子类集合返回不同类型的迭代器, 并使得迭代器与集合相匹配。
原型并不基于继承, 因此没有继承的缺点。 另一方面, 原型需要对被复制对象进行复杂的初始化。 工厂方法基于继承, 但是它不需要初始化步骤。
工厂方法是模板方法模式的一种特殊形式。 同时, 工厂方法可以作为一个大型模板方法中的一个步骤。
1.2 抽象工厂模式
- 问题
假设你正在开发一款家具商店模拟器。 你的代码中包括一些类, 用于表示:
一系列相关产品, 例如 椅子 Chair 、 沙发 Sofa 和 咖啡桌 CoffeeTable 。
系列产品的不同变体。 例如, 你可以使用 现代 Modern 、 维多利亚 Victorian 、 装饰风艺术 ArtDeco 等风格生成 椅子 、 沙发和 咖啡桌 。
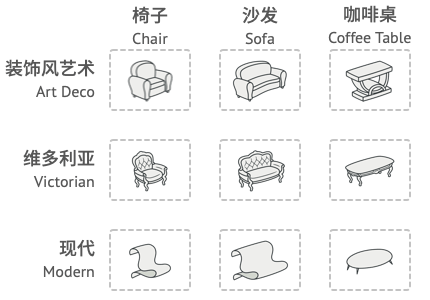
你需要设法单独生成每件家具对象, 这样才能确保其风格一致。 如果顾客收到的家具风格不一样, 他们可不会开心。
此外, 你也不希望在添加新产品或新风格时修改已有代码。 家具供应商对于产品目录的更新非常频繁, 你不会想在每次更新时都去修改核心代码的。
- 方案、架构
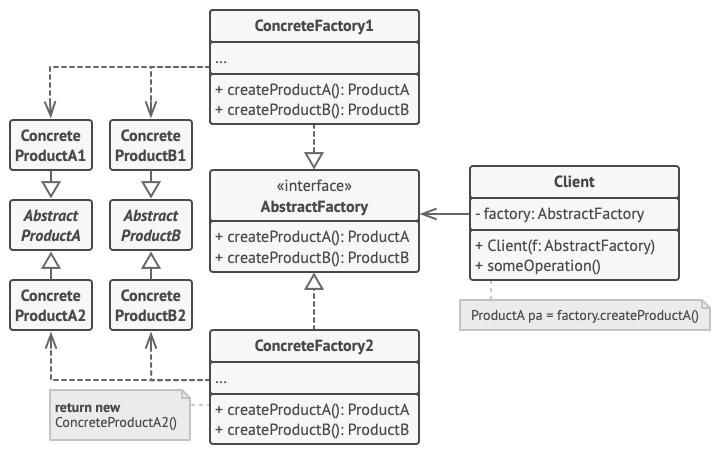
补充说明: 如果客户端仅接触抽象接口, 那么谁来创建实际的工厂对象呢? 一般情况下, 应用程序会在初始化阶段创建具体工厂对象。 而在此之前, 应用程序必须根据配置文件或环境设定选择工厂类别。
下面例子通过应用抽象工厂模式, 使得客户端代码无需与具体 UI 类耦合, 就能创建跨平台的 UI 元素, 同时确保所创建的元素与指定的操作系统匹配。
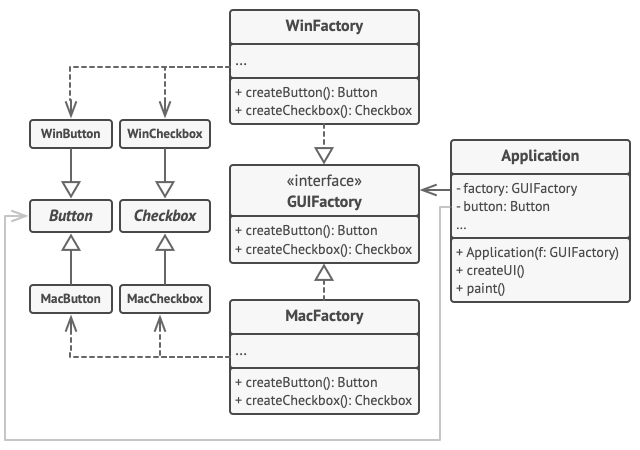
跨平台应用中的相同 UI 元素功能类似, 但是在不同操作系统下的外观有一定差异。 此外, 你需要确保 UI 元素与当前操作系统风格一致。 你一定不希望在 Windows 系统下运行的应用程序中显示 macOS 的控件。
抽象工厂接口声明一系列构建方法, 客户端代码可调用它们生成不同风格的 UI 元素。 每个具体工厂对应特定操作系统, 并负责生成符合该操作系统风格的 UI 元素。
其运作方式如下: 应用程序启动后检测当前操作系统。 根据该信息, 应用程序通过与该操作系统对应的类创建工厂对象。 其余代码使用该工厂对象创建 UI 元素。 这样可以避免生成错误类型的元素。
使用这种方法, 客户端代码只需调用抽象接口, 而无需了解具体工厂类和 UI 元素。 此外, 客户端代码还支持未来添加新的工厂或 UI 元素。
这样一来, 每次在应用程序中添加新的 UI 元素变体时, 你都无需修改客户端代码。 你只需创建一个能够生成这些 UI 元素的工厂类, 然后稍微修改应用程序的初始代码, 使其能够选择合适的工厂类即可。
- 适用场景
如果代码需要与多个不同系列的相关产品交互, 但是由于无法提前获取相关信息, 或者出于对未来扩展性的考虑, 你不希望代码基于产品的具体类进行构建, 在这种情况下, 你可以使用抽象工厂。
抽象工厂为你提供了一个接口, 可用于创建每个系列产品的对象。 只要代码通过该接口创建对象, 那么你就不会生成与应用程序已生成的产品类型不一致的产品。
如果你有一个基于一组抽象方法的类, 且其主要功能因此变得不明确, 那么在这种情况下可以考虑使用抽象工厂模式。
在设计良好的程序中, 每个类仅负责一件事。 如果一个类与多种类型产品交互, 就可以考虑将工厂方法抽取到独立的工厂类或具备完整功能的抽象工厂类中。
- 优缺点
优点
- 你可以确保同一工厂生成的产品相互匹配。
- 你可以避免客户端和具体产品代码的耦合。
- 单一职责原则。 你可以将产品生成代码抽取到同一位置, 使得代码易于维护。
- 开闭原则。 向应用程序中引入新产品变体时, 你无需修改客户端代码。
缺点
由于采用该模式需要向应用中引入众多接口和类, 代码可能会比之前更加复杂。
- 与其他模式的关系
在许多设计工作的初期都会使用工厂方法模式 (较为简单, 而且可以更方便地通过子类进行定制), 随后演化为使用抽象工厂模式、 原型模式或生成器模式 (更灵活但更加复杂)。
生成器重点关注如何分步生成复杂对象。 抽象工厂专门用于生产一系列相关对象。 抽象工厂会马上返回产品, 生成器则允许你在获取产品前执行一些额外构造步骤。
抽象工厂模式通常基于一组工厂方法, 但你也可以使用原型模式来生成这些类的方法。
当只需对客户端代码隐藏子系统创建对象的方式时, 你可以使用抽象工厂来代替外观模式。
你可以将抽象工厂和桥接模式搭配使用。 如果由桥接定义的抽象只能与特定实现合作, 这一模式搭配就非常有用。 在这种情况下, 抽象工厂可以对这些关系进行封装, 并且对客户端代码隐藏其复杂性。
抽象工厂、 生成器和原型都可以用单例模式来实现。
1.3 生成器模式
- 问题
假设有这样一个复杂对象, 在对其进行构造时需要对诸多成员变量和嵌套对象进行繁复的初始化工作。 这些初始化代码通常深藏于一个包含众多参数且让人基本看不懂的构造函数中; 甚至还有更糟糕的情况, 那就是这些代码散落在客户端代码的多个位置。
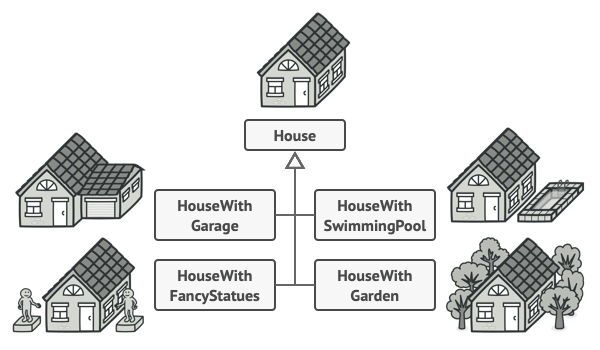
例如, 我们来思考如何创建一个 房屋House对象。 建造一栋简单的房屋, 首先你需要建造四面墙和地板, 安装房门和一套窗户, 然后再建造一个屋顶。 但是如果你想要一栋更宽敞更明亮的房屋, 还要有院子和其他设施 (例如暖气、 排水和供电设备), 那又该怎么办呢?
最简单的方法是扩展 房屋基类, 然后创建一系列涵盖所有参数组合的子类。 但最终你将面对相当数量的子类。 任何新增的参数 (例如门廊类型) 都会让这个层次结构更加复杂。
另一种方法则无需生成子类。 你可以在 房屋基类中创建一个包括所有可能参数的超级构造函数, 并用它来控制房屋对象。 这种方法确实可以避免生成子类, 但它却会造成另外一个问题。
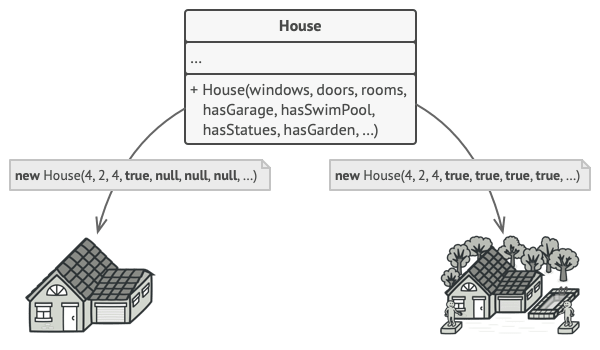
通常情况下, 绝大部分的参数都没有使用, 这使得对于构造函数的调用十分不简洁。 例如, 只有很少的房子有游泳池, 因此与游泳池相关的参数十之八九是毫无用处的。
- 方案、架构
下面关于生成器模式的例子演示了你可以如何复用相同的对象构造代码来生成不同类型的产品——例如汽车 (Car)——及其相应的使用手册 (Manual)。
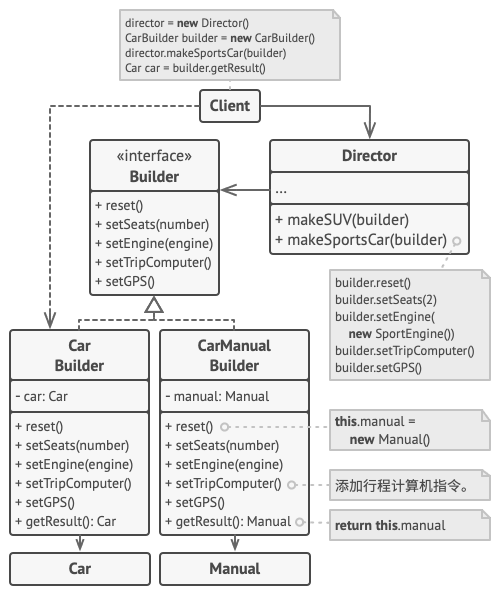
汽车是一个复杂对象, 有数百种不同的制造方法。 我们没有在 汽车类中塞入一个巨型构造函数, 而是将汽车组装代码抽取到单独的汽车生成器类中。 该类中有一组方法可用来配置汽车的各种部件。
如果客户端代码需要组装一辆与众不同、 精心调教的汽车, 它可以直接调用生成器。 或者, 客户端可以将组装工作委托给主管类, 因为主管类知道如何使用生成器制造最受欢迎的几种型号汽车。
你或许会感到吃惊, 但确实每辆汽车都需要一本使用手册 (说真的, 谁会去读它们呢?)。 使用手册会介绍汽车的每一项功能, 因此不同型号的汽车, 其使用手册内容也不一样。 因此, 你可以复用现有流程来制造实际的汽车及其对应的手册。 当然, 编写手册和制造汽车不是一回事, 所以我们需要另外一个生成器对象来专门编写使用手册。 该类与其制造汽车的兄弟类都实现了相同的制造方法, 但是其功能不是制造汽车部件, 而是描述每个部件。 将这些生成器传递给相同的主管对象, 我们就能够生成一辆汽车或是一本使用手册了。
最后一个部分是获取结果对象。 尽管金属汽车和纸质手册存在关联, 但它们却是完全不同的东西。 我们无法在主管类和具体产品类不发生耦合的情况下, 在主管类中提供获取结果对象的方法。 因此, 我们只能通过负责制造过程的生成器来获取结果对象。
- 适用场景
使用生成器模式可避免 “重叠构造函数 (telescopic constructor)” 的出现。
假设你的构造函数中有十个可选参数, 那么调用该函数会非常不方便; 因此, 你需要重载这个构造函数, 新建几个只有较少参数的简化版。 但这些构造函数仍需调用主构造函数, 传递一些默认数值来替代省略掉的参数。
C++class Pizza {Pizza(int size) { ... }Pizza(int size, boolean cheese) { ... }Pizza(int size, boolean cheese, boolean pepperoni) { ... }// ...当你希望使用代码创建不同形式的产品 (例如石头或木头房屋) 时, 可使用生成器模式。
如果你需要创建的各种形式的产品, 它们的制造过程相似且仅有细节上的差异, 此时可使用生成器模式。
基本生成器接口中定义了所有可能的制造步骤, 具体生成器将实现这些步骤来制造特定形式的产品。 同时, 主管类将负责管理制造步骤的顺序。
使用生成器构造组合树或其他复杂对象。
生成器模式让你能分步骤构造产品。 你可以延迟执行某些步骤而不会影响最终产品。 你甚至可以递归调用这些步骤, 这在创建对象树时非常方便。
生成器在执行制造步骤时, 不能对外发布未完成的产品。 这可以避免客户端代码获取到不完整结果对象的情况。
- 优缺点
优点
- 你可以分步创建对象, 暂缓创建步骤或递归运行创建步骤。
- 生成不同形式的产品时, 你可以复用相同的制造代码。
- 单一职责原则。 你可以将复杂构造代码从产品的业务逻辑中分离出来。
缺点
由于该模式需要新增多个类, 因此代码整体复杂程度会有所增加。
- 与其他模式的关系
在许多设计工作的初期都会使用工厂方法模式 (较为简单, 而且可以更方便地通过子类进行定制), 随后演化为使用抽象工厂模式、 原型模式或生成器模式 (更灵活但更加复杂)。
生成器重点关注如何分步生成复杂对象。 抽象工厂专门用于生产一系列相关对象。 抽象工厂会马上返回产品, 生成器则允许你在获取产品前执行一些额外构造步骤。
你可以在创建复杂组合模式树时使用生成器, 因为这可使其构造步骤以递归的方式运行。
你可以结合使用生成器和桥接模式: 主管类负责抽象工作, 各种不同的生成器负责实现工作。
抽象工厂、 生成器和原型都可以用单例模式来实现。
1.4 原型模式
- 问题
如果你有一个对象, 并希望生成与其完全相同的一个复制品, 你该如何实现呢? 首先, 你必须新建一个属于相同类的对象。 然后, 你必须遍历原始对象的所有成员变量, 并将成员变量值复制到新对象中。
不错! 但有个小问题。 并非所有对象都能通过这种方式进行复制, 因为有些对象可能拥有私有成员变量, 它们在对象本身以外是不可见的。
直接复制还有另外一个问题。 因为你必须知道对象所属的类才能创建复制品, 所以代码必须依赖该类。 即使你可以接受额外的依赖性, 那还有另外一个问题: 有时你只知道对象所实现的接口, 而不知道其所属的具体类, 比如可向方法的某个参数传入实现了某个接口的任何对象。
- 方案、架构
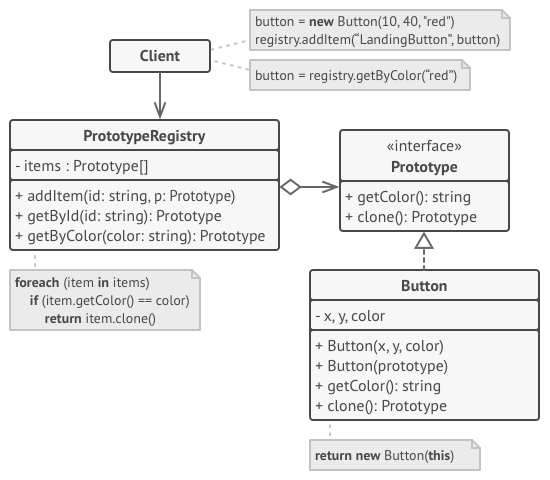
在本例中, 原型模式能让你生成完全相同的几何对象副本, 同时无需代码与对象所属类耦合。
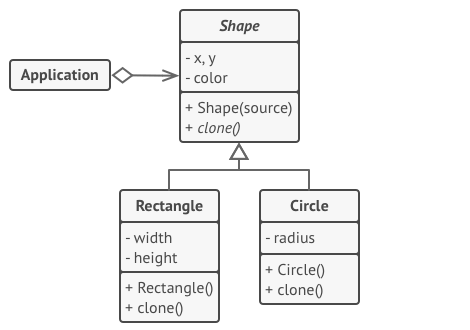
所有形状类都遵循同一个提供克隆方法的接口。 在复制自身成员变量值到结果对象前, 子类可调用其父类的克隆方法。
- 适用场景
如果你需要复制一些对象, 同时又希望代码独立于这些对象所属的具体类, 可以使用原型模式。
这一点考量通常出现在代码需要处理第三方代码通过接口传递过来的对象时。 即使不考虑代码耦合的情况, 你的代码也不能依赖这些对象所属的具体类, 因为你不知道它们的具体信息。
原型模式为客户端代码提供一个通用接口, 客户端代码可通过这一接口与所有实现了克隆的对象进行交互, 它也使得客户端代码与其所克隆的对象具体类独立开来。
如果子类的区别仅在于其对象的初始化方式, 那么你可以使用该模式来减少子类的数量。 别人创建这些子类的目的可能是为了创建特定类型的对象。
在原型模式中, 你可以使用一系列预生成的、 各种类型的对象作为原型。
客户端不必根据需求对子类进行实例化, 只需找到合适的原型并对其进行克隆即可。
- 优缺点
优点
- 你可以克隆对象, 而无需与它们所属的具体类相耦合。
- 你可以克隆预生成原型, 避免反复运行初始化代码。
- 你可以更方便地生成复杂对象。
- 你可以用继承以外的方式来处理复杂对象的不同配置。
缺点
克隆包含循环引用的复杂对象可能会非常麻烦。
- 与其他模式的关系
在许多设计工作的初期都会使用工厂方法模式 (较为简单, 而且可以更方便地通过子类进行定制), 随后演化为使用抽象工厂模式、 原型模式或生成器模式 (更灵活但更加复杂)。
抽象工厂模式通常基于一组工厂方法, 但你也可以使用原型模式来生成这些类的方法。
原型可用于保存命令模式的历史记录。
大量使用组合模式和装饰模式的设计通常可从对于原型的使用中获益。 你可以通过该模式来复制复杂结构, 而非从零开始重新构造。
原型并不基于继承, 因此没有继承的缺点。 另一方面, 原型需要对被复制对象进行复杂的初始化。 工厂方法基于继承, 但是它不需要初始化步骤。
有时候原型可以作为备忘录模式的一个简化版本, 其条件是你需要在历史记录中存储的对象的状态比较简单, 不需要链接其他外部资源, 或者链接可以方便地重建。
抽象工厂、 生成器和原型都可以用单例模式来实现。
1.5 单例模式
- 问题
单例模式同时解决了两个问题, 所以违反了单一职责原则:
- 保证一个类只有一个实例。 为什么会有人想要控制一个类所拥有的实例数量? 最常见的原因是控制某些共享资源 (例如数据库或文件) 的访问权限。
它的运作方式是这样的: 如果你创建了一个对象, 同时过一会儿后你决定再创建一个新对象, 此时你会获得之前已创建的对象, 而不是一个新对象。
注意, 普通构造函数无法实现上述行为, 因为构造函数的设计决定了它必须总是返回一个新对象。
- 为该实例提供一个全局访问节点。 还记得你 (好吧, 其实是我自己) 用过的那些存储重要对象的全局变量吗? 它们在使用上十分方便, 但同时也非常不安全, 因为任何代码都有可能覆盖掉那些变量的内容, 从而引发程序崩溃。
和全局变量一样, 单例模式也允许在程序的任何地方访问特定对象。 但是它可以保护该实例不被其他代码覆盖。
还有一点: 你不会希望解决同一个问题的代码分散在程序各处的。 因此更好的方式是将其放在同一个类中, 特别是当其他代码已经依赖这个类时更应该如此。
如今, 单例模式已经变得非常流行, 以至于人们会将只解决上文描述中任意一个问题的东西称为单例。
- 方案、架构
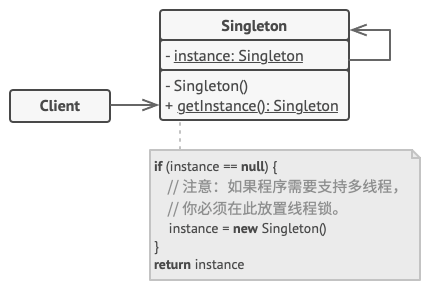
单例 (Singleton) 类声明了一个名为 getInstance获取实例的静态方法来返回其所属类的一个相同实例。
单例的构造函数必须对客户端 (Client) 代码隐藏。 调用 获取实例方法必须是获取单例对象的唯一方式。
- 适用场景
如果程序中的某个类对于所有客户端只有一个可用的实例, 可以使用单例模式。
单例模式禁止通过除特殊构建方法以外的任何方式来创建自身类的对象。 该方法可以创建一个新对象, 但如果该对象已经被创建, 则返回已有的对象。
如果你需要更加严格地控制全局变量, 可以使用单例模式。
单例模式与全局变量不同, 它保证类只存在一个实例。 除了单例类自己以外, 无法通过任何方式替换缓存的实例。
请注意, 你可以随时调整限制并设定生成单例实例的数量, 只需修改 获取实例方法, 即 getInstance 中的代码即可实现。
- 优缺点
优点
- 你可以保证一个类只有一个实例。
- 你获得了一个指向该实例的全局访问节点。
- 仅在首次请求单例对象时对其进行初始化。
缺点
- 违反了单一职责原则。 该模式同时解决了两个问题。
- 单例模式可能掩盖不良设计, 比如程序各组件之间相互了解过多等。
- 该模式在多线程环境下需要进行特殊处理, 避免多个线程多次创建单例对象。
- 单例的客户端代码单元测试可能会比较困难, 因为许多测试框架以基于继承的方式创建模拟对象。 由于单例类的构造函数是私有的, 而且绝大部分语言无法重写静态方法, 所以你需要想出仔细考虑模拟单例的方法。 要么干脆不编写测试代码, 或者不使用单例模式。
- 与其他模式的关系
外观模式类通常可以转换为单例模式类, 因为在大部分情况下一个外观对象就足够了。
如果你能将对象的所有共享状态简化为一个享元对象, 那么享元模式就和单例类似了。 但这两个模式有两个根本性的不同。
2.1 只会有一个单例实体, 但是享元类可以有多个实体, 各实体的内在状态也可以不同。
2.2 单例对象可以是可变的。 享元对象是不可变的。
抽象工厂模式、 生成器模式和原型模式都可以用单例来实现。
2.1 适配器模式
- 问题
假如你正在开发一款股票市场监测程序, 它会从不同来源下载 XML 格式的股票数据, 然后向用户呈现出美观的图表。
在开发过程中, 你决定在程序中整合一个第三方智能分析函数库。 但是遇到了一个问题, 那就是分析函数库只兼容 JSON 格式的数据。
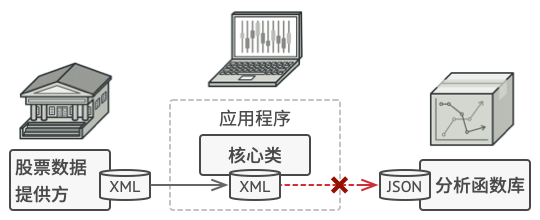
你可以修改程序库来支持 XML。 但是, 这可能需要修改部分依赖该程序库的现有代码。 甚至还有更糟糕的情况, 你可能根本没有程序库的源代码, 从而无法对其进行修改。
- 方案、架构
你可以创建一个适配器。 这是一个特殊的对象, 能够转换对象接口, 使其能与其他对象进行交互。
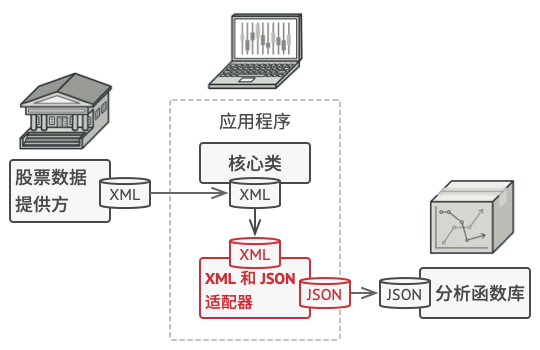
有时你甚至可以创建一个双向适配器来实现双向转换调用。
适配器可以有两种类型:
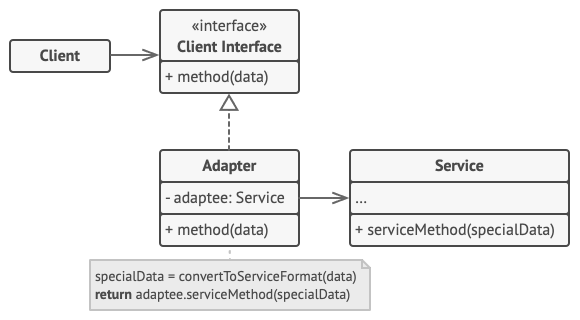
- 对象适配器
实现时使用了构成原则: 适配器实现了其中一个对象的接口, 并对另一个对象进行封装。 所有流行的编程语言都可以实现适配器。
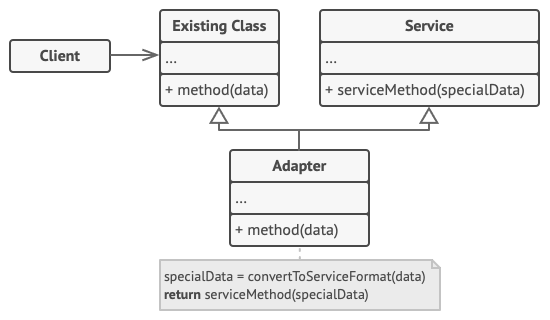
- 类适配器
这一实现使用了继承机制: 适配器同时继承两个对象的接口。 请注意, 这种方式仅能在支持多重继承的编程语言中实现, 例如 C++。
事实上 JS/TS 也支持多重继承,毕竟 JS 的 class 只是一个语法糖,可以较为轻松的操作类原型属性,使其只是类成员变量的拓展
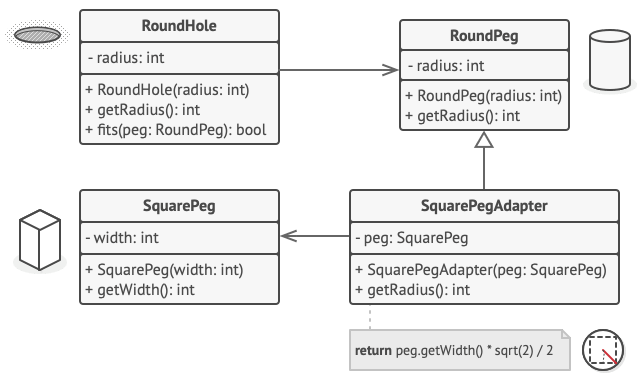
下列适配器模式演示基于经典的 “方钉和圆孔” 问题。
- 适用场景
当你希望使用某个类, 但是其接口与其他代码不兼容时, 可以使用适配器类。
适配器模式允许你创建一个中间层类, 其可作为代码与遗留类、 第三方类或提供怪异接口的类之间的转换器。
如果您需要复用这样一些类, 他们处于同一个继承体系, 并且他们又有了额外的一些共同的方法, 但是这些共同的方法不是所有在这一继承体系中的子类所具有的共性。
你可以扩展每个子类, 将缺少的功能添加到新的子类中。 但是, 你必须在所有新子类中重复添加这些代码, 这样会使得代码有坏味道。
将缺失功能添加到一个适配器类中是一种优雅得多的解决方案。 然后你可以将缺少功能的对象封装在适配器中, 从而动态地获取所需功能。 如要这一点正常运作, 目标类必须要有通用接口, 适配器的成员变量应当遵循该通用接口。 这种方式同装饰模式非常相似。
- 优缺点
优点
- 单一职责原则你可以将接口或数据转换代码从程序主要业务逻辑中分离。
- 开闭原则。 只要客户端代码通过客户端接口与适配器进行交互, 你就能在不修改现有客户端代码的情况下在程序中添加新类型的适配器。
缺点
代码整体复杂度增加, 因为你需要新增一系列接口和类。 有时直接更改服务类使其与其他代码兼容会更简单。
- 与其他模式的关系
桥接模式通常会于开发前期进行设计, 使你能够将程序的各个部分独立开来以便开发。 另一方面, 适配器模式通常在已有程序中使用, 让相互不兼容的类能很好地合作。
适配器可以对已有对象的接口进行修改, 装饰模式则能在不改变对象接口的前提下强化对象功能。 此外, 装饰还支持递归组合, 适配器则无法实现。
适配器能为被封装对象提供不同的接口, 代理模式能为对象提供相同的接口, 装饰则能为对象提供加强的接口。
外观模式为现有对象定义了一个新接口, 适配器则会试图运用已有的接口。 适配器通常只封装一个对象, 外观通常会作用于整个对象子系统上。
桥接、 状态模式和策略模式 (在某种程度上包括适配器) 模式的接口非常相似。 实际上, 它们都基于组合模式——即将工作委派给其他对象, 不过也各自解决了不同的问题。 模式并不只是以特定方式组织代码的配方, 你还可以使用它们来和其他开发者讨论模式所解决的问题。
2.2 桥接模式
- 问题
假如你有一个几何 形状Shape类, 从它能扩展出两个子类: 圆形Circle和 方形Square 。 你希望对这样的类层次结构进行扩展以使其包含颜色, 所以你打算创建名为 红色Red和 蓝色Blue的形状子类。 但是, 由于你已有两个子类, 所以总共需要创建四个类才能覆盖所有组合, 例如 蓝色圆形BlueCircle和 红色方形RedSquare 。
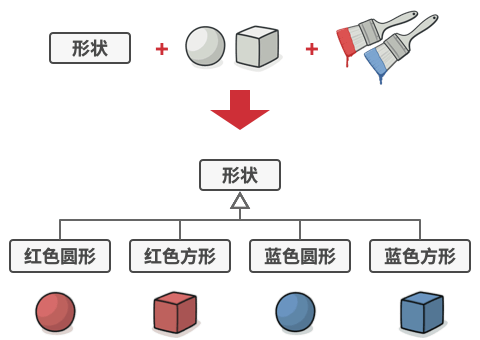
在层次结构中新增形状和颜色将导致代码复杂程度指数增长。 例如添加三角形状, 你需要新增两个子类, 也就是每种颜色一个; 此后新增一种新颜色需要新增三个子类, 即每种形状一个。 如此以往, 情况会越来越糟糕。
- 方案、架构
示例演示了桥接模式如何拆分程序中同时管理设备及其遥控器的庞杂代码。 设备Device类作为实现部分, 而 遥控器Remote类则作为抽象部分。
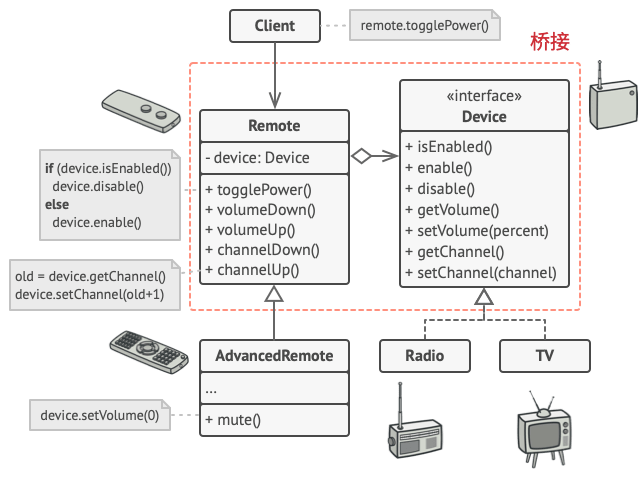
遥控器基类声明了一个指向设备对象的引用成员变量。 所有遥控器通过通用设备接口与设备进行交互, 使得同一个遥控器可以支持不同类型的设备。
你可以开发独立于设备类的遥控器类, 只需新建一个遥控器子类即可。 例如, 基础遥控器可能只有两个按钮, 但你可在其基础上扩展新功能, 比如额外的一节电池或一块触摸屏。
客户端代码通过遥控器构造函数将特定种类的遥控器与设备对象连接起来。
- 适用场景
如果你想要拆分或重组一个具有多重功能的庞杂类 (例如能与多个数据库服务器进行交互的类), 可以使用桥接模式。
类的代码行数越多, 弄清其运作方式就越困难, 对其进行修改所花费的时间就越长。 一个功能上的变化可能需要在整个类范围内进行修改, 而且常常会产生错误, 甚至还会有一些严重的副作用。
桥接模式可以将庞杂类拆分为几个类层次结构。 此后, 你可以修改任意一个类层次结构而不会影响到其他类层次结构。 这种方法可以简化代码的维护工作, 并将修改已有代码的风险降到最低。
如果你希望在几个独立维度上扩展一个类, 可使用该模式。
桥接建议将每个维度抽取为独立的类层次。 初始类将相关工作委派给属于对应类层次的对象, 无需自己完成所有工作。
如果你需要在运行时切换不同实现方法, 可使用桥接模式。
当然并不是说一定要实现这一点, 桥接模式可替换抽象部分中的实现对象, 具体操作就和给成员变量赋新值一样简单。
顺便提一句, 最后一点是很多人混淆桥接模式和策略模式的主要原因。 记住, 设计模式并不仅是一种对类进行组织的方式, 它还能用于沟通意图和解决问题。
- 优缺点
优点
- 你可以创建与平台无关的类和程序。
- 客户端代码仅与高层抽象部分进行互动, 不会接触到平台的详细信息。
- 开闭原则。 你可以新增抽象部分和实现部分, 且它们之间不会相互影响。
- 单一职责原则。 抽象部分专注于处理高层逻辑, 实现部分处理平台细节。
缺点
对高内聚的类使用该模式可能会让代码更加复杂。
- 与其他模式的关系
桥接模式通常会于开发前期进行设计, 使你能够将程序的各个部分独立开来以便开发。 另一方面, 适配器模式通常在已有程序中使用, 让相互不兼容的类能很好地合作。
桥接、 状态模式和策略模式 (在某种程度上包括适配器) 模式的接口非常相似。 实际上, 它们都基于组合模式——即将工作委派给其他对象, 不过也各自解决了不同的问题。 模式并不只是以特定方式组织代码的配方, 你还可以使用它们来和其他开发者讨论模式所解决的问题。
你可以将抽象工厂模式和桥接搭配使用。 如果由桥接定义的抽象只能与特定实现合作, 这一模式搭配就非常有用。 在这种情况下, 抽象工厂可以对这些关系进行封装, 并且对客户端代码隐藏其复杂性。
你可以结合使用生成器模式和桥接模式: 主管类负责抽象工作, 各种不同的生成器负责实现工作。
2.3 组合模式
- 问题
如果应用的核心模型能用树状结构表示, 在应用中使用组合模式才有价值。
例如, 你有两类对象: 产品和 盒子 。 一个盒子中可以包含多个 产品或者几个较小的 盒子 。 这些小 盒子中同样可以包含一些 产品或更小的 盒子 , 以此类推。
假设你希望在这些类的基础上开发一个定购系统。 订单中可以包含无包装的简单产品, 也可以包含装满产品的盒子……以及其他盒子。 此时你会如何计算每张订单的总价格呢?
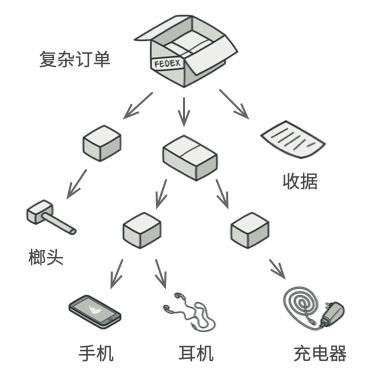
你可以尝试直接计算: 打开所有盒子, 找到每件产品, 然后计算总价。 这在真实世界中或许可行, 但在程序中, 你并不能简单地使用循环语句来完成该工作。 你必须事先知道所有 产品和 盒子的类别, 所有盒子的嵌套层数以及其他繁杂的细节信息。 因此, 直接计算极不方便, 甚至完全不可行。
- 方案、架构
该方式的最大优点在于你无需了解构成树状结构的对象的具体类。 你也无需了解对象是简单的产品还是复杂的盒子。 你只需调用通用接口以相同的方式对其进行处理即可。 当你调用该方法后, 对象会将请求沿着树结构传递下去。
在本例中, 我们将借助组合模式帮助你在图形编辑器中实现一系列的几何图形。
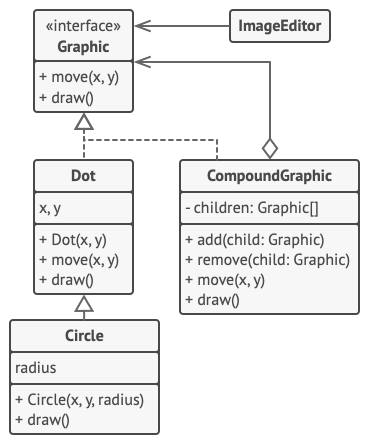
组合图形CompoundGraphic是一个容器, 它可以由多个包括容器在内的子图形构成。 组合图形与简单图形拥有相同的方法。 但是, 组合图形自身并不完成具体工作, 而是将请求递归地传递给自己的子项目, 然后 “汇总” 结果。
通过所有图形类所共有的接口, 客户端代码可以与所有图形互动。 因此, 客户端不知道与其交互的是简单图形还是组合图形。 客户端可以与非常复杂的对象结构进行交互, 而无需与组成该结构的实体类紧密耦合。
- 适用场景
如果你需要实现树状对象结构, 可以使用组合模式。
组合模式为你提供了两种共享公共接口的基本元素类型: 简单叶节点和复杂容器。 容器中可以包含叶节点和其他容器。 这使得你可以构建树状嵌套递归对象结构。
如果你希望客户端代码以相同方式处理简单和复杂元素, 可以使用该模式。
组合模式中定义的所有元素共用同一个接口。 在这一接口的帮助下, 客户端不必在意其所使用的对象的具体类。
- 优缺点
优点
- 你可以利用多态和递归机制更方便地使用复杂树结构。
- 开闭原则。 无需更改现有代码, 你就可以在应用中添加新元素, 使其成为对象树的一部分。
缺点
对于功能差异较大的类, 提供公共接口或许会有困难。 在特定情况下, 你需要过度一般化组件接口, 使其变得令人难以理解。
- 与其他模式的关系
桥接模式、 状态模式和策略模式 (在某种程度上包括适配器模式) 模式的接口非常相似。 实际上, 它们都基于组合模式——即将工作委派给其他对象, 不过也各自解决了不同的问题。 模式并不只是以特定方式组织代码的配方, 你还可以使用它们来和其他开发者讨论模式所解决的问题。
你可以在创建复杂组合树时使用生成器模式, 因为这可使其构造步骤以递归的方式运行。
责任链模式通常和组合模式结合使用。 在这种情况下, 叶组件接收到请求后, 可以将请求沿包含全体父组件的链一直传递至对象树的底部。
你可以使用迭代器模式来遍历组合树。
你可以使用访问者模式对整个组合树执行操作。
你可以使用享元模式实现组合树的共享叶节点以节省内存。
组合和装饰模式的结构图很相似, 因为两者都依赖递归组合来组织无限数量的对象。
装饰类似于组合, 但其只有一个子组件。 此外还有一个明显不同: 装饰为被封装对象添加了额外的职责, 组合仅对其子节点的结果进行了 “求和”。
但是, 模式也可以相互合作: 你可以使用装饰来扩展组合树中特定对象的行为。
大量使用组合和装饰的设计通常可从对于原型模式的使用中获益。 你可以通过该模式来复制复杂结构, 而非从零开始重新构造。
2.4 装饰模式
- 问题
假设你正在开发一个提供通知功能的库, 其他程序可使用它向用户发送关于重要事件的通知。
库的最初版本基于 通知器Notifier类, 其中只有很少的几个成员变量, 一个构造函数和一个 send发送方法。 该方法可以接收来自客户端的消息参数, 并将该消息发送给一系列的邮箱, 邮箱列表则是通过构造函数传递给通知器的。 作为客户端的第三方程序仅会创建和配置通知器对象一次, 然后在有重要事件发生时对其进行调用。
程序可以使用通知器类向预定义的邮箱发送重要事件通知。
此后某个时刻, 你会发现库的用户希望使用除邮件通知之外的功能。 许多用户会希望接收关于紧急事件的手机短信, 还有些用户希望在微信上接收消息, 而公司用户则希望在 QQ 上接收消息。
每种通知类型都将作为通知器的一个子类得以实现。
这有什么难的呢? 首先扩展 通知器类, 然后在新的子类中加入额外的通知方法。 现在客户端要对所需通知形式的对应类进行初始化, 然后使用该类发送后续所有的通知消息。
但是很快有人会问: “为什么不同时使用多种通知形式呢? 如果房子着火了, 你大概会想在所有渠道中都收到相同的消息吧。”
你可以尝试创建一个特殊子类来将多种通知方法组合在一起以解决该问题。 但这种方式会使得代码量迅速膨胀, 不仅仅是程序库代码, 客户端代码也会如此。
子类组合数量爆炸。
你必须找到其他方法来规划通知类的结构, 否则它们的数量会在不经意之间打破吉尼斯纪录。
当你需要更改一个对象的行为时, 第一个跳入脑海的想法就是扩展它所属的类。 但是, 你不能忽视继承可能引发的几个严重问题。
继承是静态的。 你无法在运行时更改已有对象的行为, 只能使用由不同子类创建的对象来替代当前的整个对象。
子类只能有一个父类。 大部分编程语言不允许一个类同时继承多个类的行为。
其中一种方法是用聚合或组合 , 而不是继承。 两者的工作方式几乎一模一样: 一个对象包含指向另一个对象的引用, 并将部分工作委派给引用对象; 继承中的对象则继承了父类的行为, 它们自己能够完成这些工作。
你可以使用这个新方法来轻松替换各种连接的 “小帮手” 对象, 从而能在运行时改变容器的行为。 一个对象可以使用多个类的行为, 包含多个指向其他对象的引用, 并将各种工作委派给引用对象。
聚合 (或组合) 组合是许多设计模式背后的关键原则 (包括装饰在内)。 记住这一点后, 让我们继续关于模式的讨论。
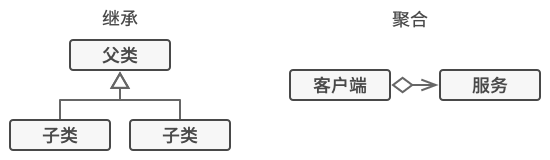
- 方案、架构
封装器是装饰模式的别称, 这个称谓明确地表达了该模式的主要思想。 “封装器” 是一个能与其他 “目标” 对象连接的对象。 封装器包含与目标对象相同的一系列方法, 它会将所有接收到的请求委派给目标对象。 但是, 封装器可以在将请求委派给目标前后对其进行处理, 所以可能会改变最终结果。
那么什么时候一个简单的封装器可以被称为是真正的装饰呢? 正如之前提到的, 封装器实现了与其封装对象相同的接口。 因此从客户端的角度来看, 这些对象是完全一样的。 封装器中的引用成员变量可以是遵循相同接口的任意对象。 这使得你可以将一个对象放入多个封装器中, 并在对象中添加所有这些封装器的组合行为。
比如在消息通知示例中, 我们可以将简单邮件通知行为放在基类 通知器中, 但将所有其他通知方法放入装饰中。
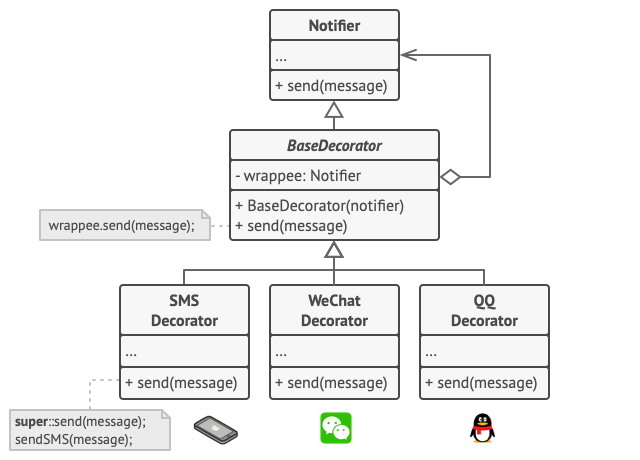
客户端代码必须将基础通知器放入一系列自己所需的装饰中。 因此最后的对象将形成一个栈结构。
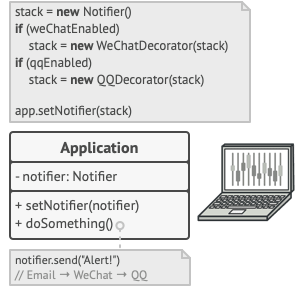
实际与客户端进行交互的对象将是最后一个进入栈中的装饰对象。 由于所有的装饰都实现了与通知基类相同的接口, 客户端的其他代码并不在意自己到底是与 “纯粹” 的通知器对象, 还是与装饰后的通知器对象进行交互。
我们可以使用相同方法来完成其他行为 (例如设置消息格式或者创建接收人列表)。 只要所有装饰都遵循相同的接口, 客户端就可以使用任意自定义的装饰来装饰对象。
在本例中, *装饰模式能够对敏感数据进行压缩和加密, 从而将数据从使用数据的代码中独立出来。
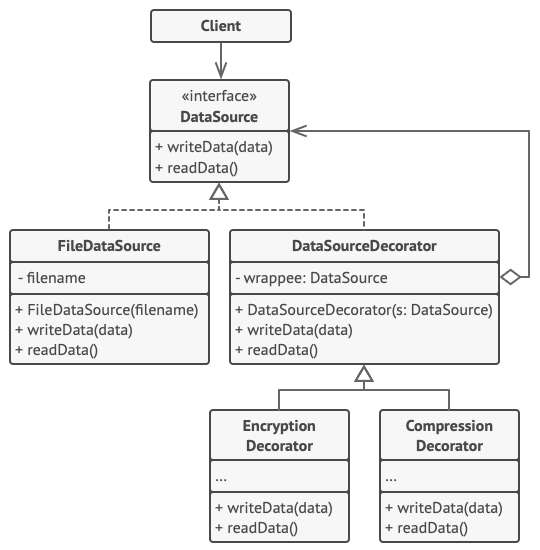
程序使用一对装饰来封装数据源对象。 这两个封装器都改变了从磁盘读写数据的方式:
当数据即将被写入磁盘前, 装饰对数据进行加密和压缩。 在原始类对改变毫无察觉的情况下, 将加密后的受保护数据写入文件。
当数据刚从磁盘读出后, 同样通过装饰对数据进行解压和解密。 装饰和数据源类实现同一接口, 从而能在客户端代码中相互替换。
- 适用场景
如果你希望在无需修改代码的情况下即可使用对象, 且希望在运行时为对象新增额外的行为, 可以使用装饰模式。
装饰能将业务逻辑组织为层次结构, 你可为各层创建一个装饰, 在运行时将各种不同逻辑组合成对象。 由于这些对象都遵循通用接口, 客户端代码能以相同的方式使用这些对象。
如果用继承来扩展对象行为的方案难以实现或者根本不可行, 你可以使用该模式。
许多编程语言使用 final最终关键字来限制对某个类的进一步扩展。 复用最终类已有行为的唯一方法是使用装饰模式: 用封装器对其进行封装。
- 优缺点
优点
- 你无需创建新子类即可扩展对象的行为。
- 你可以在运行时添加或删除对象的功能。
- 你可以用多个装饰封装对象来组合几种行为。
- 单一职责原则。 你可以将实现了许多不同行为的一个大类拆分为多个较小的类。
缺点
- 在封装器栈中删除特定封装器比较困难。
- 实现行为不受装饰栈顺序影响的装饰比较困难。
- 各层的初始化配置代码看上去可能会很糟糕。
- 与其他模式的关系
适配器模式可以对已有对象的接口进行修改, 装饰模式则能在不改变对象接口的前提下强化对象功能。 此外, 装饰还支持递归组合, 适配器则无法实现。
适配器能为被封装对象提供不同的接口, 代理模式能为对象提供相同的接口, 装饰则能为对象提供加强的接口。
责任链模式和装饰模式的类结构非常相似。 两者都依赖递归组合将需要执行的操作传递给一系列对象。 但是, 两者有几点重要的不同之处。
责任链的管理者可以相互独立地执行一切操作, 还可以随时停止传递请求。 另一方面, 各种装饰可以在遵循基本接口的情况下扩展对象的行为。 此外, 装饰无法中断请求的传递。
组合模式和装饰的结构图很相似, 因为两者都依赖递归组合来组织无限数量的对象。
装饰类似于组合, 但其只有一个子组件。 此外还有一个明显不同: 装饰为被封装对象添加了额外的职责, 组合仅对其子节点的结果进行了 “求和”。
但是, 模式也可以相互合作: 你可以使用装饰来扩展组合树中特定对象的行为。
大量使用组合和装饰的设计通常可从对于原型模式的使用中获益。 你可以通过该模式来复制复杂结构, 而非从零开始重新构造。
装饰可让你更改对象的外表, 策略模式则让你能够改变其本质。
装饰和代理有着相似的结构, 但是其意图却非常不同。 这两个模式的构建都基于组合原则, 也就是说一个对象应该将部分工作委派给另一个对象。 两者之间的不同之处在于代理通常自行管理其服务对象的生命周期, 而装饰的生成则总是由客户端进行控制。
2.5 外观模式
- 问题
假设你必须在代码中使用某个复杂的库或框架中的众多对象。 正常情况下, 你需要负责所有对象的初始化工作、 管理其依赖关系并按正确的顺序执行方法等。
最终, 程序中类的业务逻辑将与第三方类的实现细节紧密耦合, 使得理解和维护代码的工作很难进行。
- 方案、架构
外观类为包含许多活动部件的复杂子系统提供一个简单的接口。 与直接调用子系统相比, 外观提供的功能可能比较有限, 但它却包含了客户端真正关心的功能。
如果你的程序需要与包含几十种功能的复杂库整合, 但只需使用其中非常少的功能, 那么使用外观模式会非常方便,
例如, 上传猫咪搞笑短视频到社交媒体网站的应用可能会用到专业的视频转换库, 但它只需使用一个包含 encode(filename, format)方法 (以文件名与文件格式为参数进行编码的方法) 的类即可。 在创建这个类并将其连接到视频转换库后, 你就拥有了自己的第一个外观。
在本例中, 外观模式简化了客户端与复杂视频转换框架之间的交互。
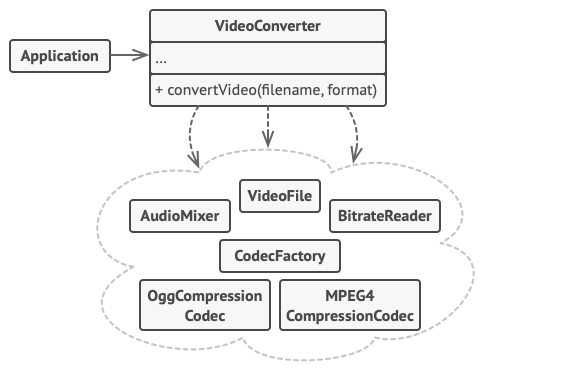
你可以创建一个封装所需功能并隐藏其他代码的外观类, 从而无需使全部代码直接与数十个框架类进行交互。 该结构还能将未来框架升级或更换所造成的影响最小化, 因为你只需修改程序中外观方法的实现即可。
- 适用场景
如果你需要一个指向复杂子系统的直接接口, 且该接口的功能有限, 则可以使用外观模式。
子系统通常会随着时间的推进变得越来越复杂。 即便是应用了设计模式, 通常你也会创建更多的类。 尽管在多种情形中子系统可能是更灵活或易于复用的, 但其所需的配置和样板代码数量将会增长得更快。 为了解决这个问题, 外观将会提供指向子系统中最常用功能的快捷方式, 能够满足客户端的大部分需求。
如果需要将子系统组织为多层结构, 可以使用外观。
创建外观来定义子系统中各层次的入口。 你可以要求子系统仅使用外观来进行交互, 以减少子系统之间的耦合。
让我们回到视频转换框架的例子。 该框架可以拆分为两个层次: 音频相关和视频相关。 你可以为每个层次创建一个外观, 然后要求各层的类必须通过这些外观进行交互。 这种方式看上去与中介者模式非常相似。
- 优缺点
优点
你可以让自己的代码独立于复杂子系统。
缺点
外观可能成为与程序中所有类都耦合的上帝对象。
- 与其他模式的关系
外观模式为现有对象定义了一个新接口, 适配器模式则会试图运用已有的接口。 适配器通常只封装一个对象, 外观通常会作用于整个对象子系统上。
当只需对客户端代码隐藏子系统创建对象的方式时, 你可以使用抽象工厂模式来代替外观。
享元模式展示了如何生成大量的小型对象, 外观则展示了如何用一个对象来代表整个子系统。
外观和中介者模式的职责类似: 它们都尝试在大量紧密耦合的类中组织起合作。
外观为子系统中的所有对象定义了一个简单接口, 但是它不提供任何新功能。 子系统本身不会意识到外观的存在。 子系统中的对象可以直接进行交流。
中介者将系统中组件的沟通行为中心化。 各组件只知道中介者对象, 无法直接相互交流。
外观类通常可以转换为单例模式类, 因为在大部分情况下一个外观对象就足够了。
外观与代理模式的相似之处在于它们都缓存了一个复杂实体并自行对其进行初始化。 代理与其服务对象遵循同一接口, 使得自己和服务对象可以互换, 在这一点上它与外观不同。
2.6 享元模式
- 问题
假如你希望在长时间工作后放松一下, 所以开发了一款简单的游戏: 玩家们在地图上移动并相互射击。 你决定实现一个真实的粒子系统, 并将其作为游戏的特色。 大量的子弹、 导弹和爆炸弹片会在整个地图上穿行, 为玩家提供紧张刺激的游戏体验。
开发完成后, 你推送提交了最新版本的程序, 并在编译游戏后将其发送给了一个朋友进行测试。 尽管该游戏在你的电脑上完美运行, 但是你的朋友却无法长时间进行游戏: 游戏总是会在他的电脑上运行几分钟后崩溃。 在研究了几个小时的调试消息记录后, 你发现导致游戏崩溃的原因是内存容量不足。 朋友的设备性能远比不上你的电脑, 因此游戏运行在他的电脑上时很快就会出现问题。
真正的问题与粒子系统有关。 每个粒子 (一颗子弹、 一枚导弹或一块弹片) 都由包含完整数据的独立对象来表示。 当玩家在游戏中鏖战进入高潮后的某一时刻, 游戏将无法在剩余内存中载入新建粒子, 于是程序就崩溃了。
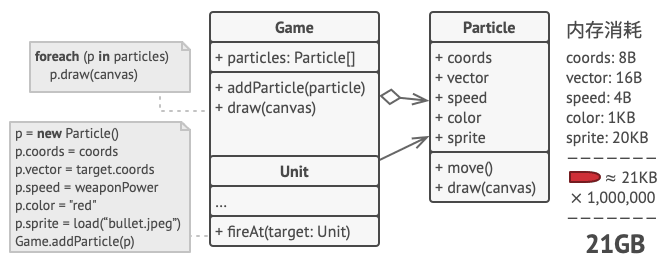
- 方案、架构
仔细观察 粒子Particle类, 你可能会注意到颜色 (color) 和精灵图 (sprite)这两个成员变量所消耗的内存要比其他变量多得多。 更糟糕的是, 对于所有的粒子来说, 这两个成员变量所存储的数据几乎完全一样 (比如所有子弹的颜色和精灵图都一样)。
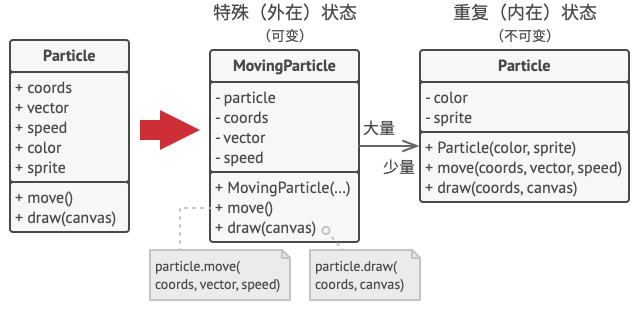
每个粒子的另一些状态 (坐标、 移动矢量和速度) 则是不同的。 因为这些成员变量的数值会不断变化。 这些数据代表粒子在存续期间不断变化的情景, 但每个粒子的颜色和精灵图则会保持不变。
对象的常量数据通常被称为内在状态, 其位于对象中, 其他对象只能读取但不能修改其数值。 而对象的其他状态常常能被其他对象 “从外部” 改变, 因此被称为外在状态。
享元模式建议不在对象中存储外在状态, 而是将其传递给依赖于它的一个特殊方法。 程序只在对象中保存内在状态, 以方便在不同情景下重用。 这些对象的区别仅在于其内在状态 (与外在状态相比, 内在状态的变体要少很多), 因此你所需的对象数量会大大削减。
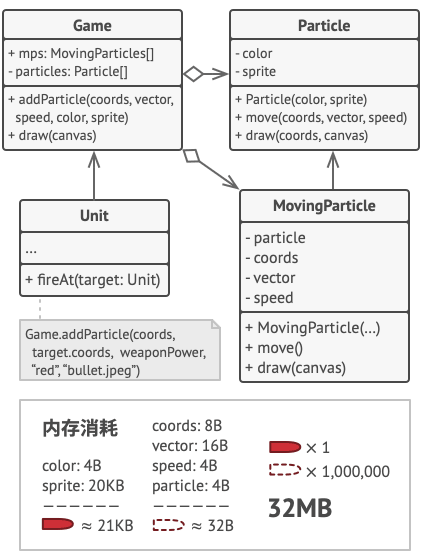
让我们回到游戏中。 假如能从粒子类中抽出外在状态, 那么我们只需三个不同的对象 (子弹、 导弹和弹片) 就能表示游戏中的所有粒子。 你现在很可能已经猜到了, 我们将这样一个仅存储内在状态的对象称为享元。
那么外在状态会被移动到什么地方呢? 总得有类来存储它们, 对不对? 在大部分情况中, 它们会被移动到容器对象中, 也就是我们应用享元模式前的聚合对象中。
在我们的例子中, 容器对象就是主要的 游戏Game对象, 其会将所有粒子存储在名为 粒子particles的成员变量中。 为了能将外在状态移动到这个类中, 你需要创建多个数组成员变量来存储每个粒子的坐标、 方向矢量和速度。 除此之外, 你还需要另一个数组来存储指向代表粒子的特定享元的引用。 这些数组必须保持同步, 这样你才能够使用同一索引来获取关于某个粒子的所有数据。
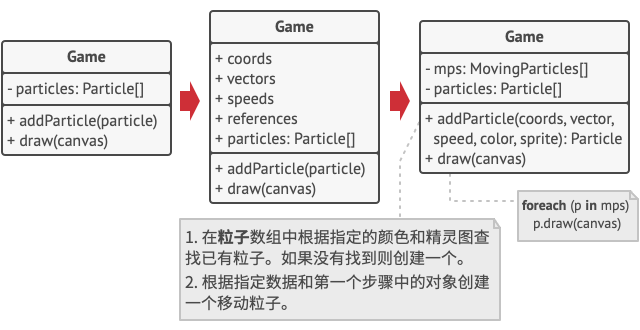
更优雅的解决方案是创建独立的情景类来存储外在状态和对享元对象的引用。 在该方法中, 容器类只需包含一个数组。
在本例中, 享元模式能有效减少在画布上渲染数百万个树状对象时所需的内存。
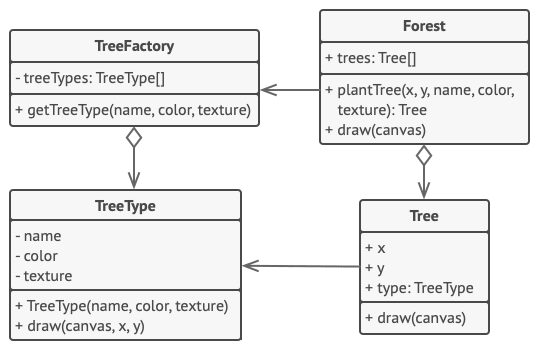
该模式从主要的 树Tree类中抽取内在状态, 并将其移动到享元类 树种类TreeType之中。
最初程序需要在多个对象中存储相同数据, 而现在仅需在几个享元对象中保存数据, 然后在作为情景的 树对象中连入享元即可。 客户端代码使用享元工厂创建树对象并封装搜索指定对象的复杂行为, 并能在需要时复用对象。
- 适用场景
仅在程序必须支持大量对象且没有足够的内存容量时使用享元模式。
应用该模式所获的收益大小取决于使用它的方式和情景。 它在下列情况中最有效:
- 程序需要生成数量巨大的相似对象
- 这将耗尽目标设备的所有内存
- 对象中包含可抽取且能在多个对象间共享的重复状态。
- 优缺点
优点
如果程序中有很多相似对象, 那么你将可以节省大量内存。
缺点
- 你可能需要牺牲执行速度来换取内存, 因为他人每次调用享元方法时都需要重新计算部分情景数据。
- 代码会变得更加复杂。 团队中的新成员总是会问: “为什么要像这样拆分一个实体的状态?”。
- 与其他模式的关系
你可以使用享元模式实现组合模式树的共享叶节点以节省内存。
享元展示了如何生成大量的小型对象, 外观模式则展示了如何用一个对象来代表整个子系统。
如果你能将对象的所有共享状态简化为一个享元对象, 那么享元就和单例模式类似了。 但这两个模式有两个根本性的不同。
3.1 只会有一个单例实体, 但是享元类可以有多个实体, 各实体的内在状态也可以不同。
3.2 单例对象可以是可变的。 享元对象是不可变的。
2.7 代理模式
- 问题
为什么要控制对于某个对象的访问呢? 举个例子: 有这样一个消耗大量系统资源的巨型对象, 你只是偶尔需要使用它, 并非总是需要。

你可以实现延迟初始化: 在实际有需要时再创建该对象。 对象的所有客户端都要执行延迟初始代码。 不幸的是, 这很可能会带来很多重复代码。
在理想情况下, 我们希望将代码直接放入对象的类中, 但这并非总是能实现: 比如类可能是第三方封闭库的一部分。
- 方案、架构
代理模式建议新建一个与原服务对象接口相同的代理类, 然后更新应用以将代理对象传递给所有原始对象客户端。 代理类接收到客户端请求后会创建实际的服务对象, 并将所有工作委派给它。

这有什么好处呢? 如果需要在类的主要业务逻辑前后执行一些工作, 你无需修改类就能完成这项工作。 由于代理实现的接口与原类相同, 因此你可将其传递给任何一个使用实际服务对象的客户端。
本例演示如何使用代理模式在第三方腾讯视频 (TencentVideo, 代码示例中记为 TV) 程序库中添加延迟初始化和缓存。
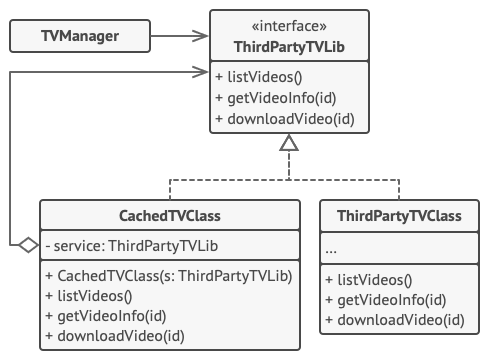
程序库提供了视频下载类。 但是该类的效率非常低。 如果客户端程序多次请求同一视频, 程序库会反复下载该视频, 而不会将首次下载的文件缓存下来复用。
代理类实现和原下载器相同的接口, 并将所有工作委派给原下载器。 不过, 代理类会保存所有的文件下载记录, 如果程序多次请求同一文件, 它会返回缓存的文件。
- 适用场景
延迟初始化 (虚拟代理)。 如果你有一个偶尔使用的重量级服务对象, 一直保持该对象运行会消耗系统资源时, 可使用代理模式。
你无需在程序启动时就创建该对象, 可将对象的初始化延迟到真正有需要的时候。
访问控制 (保护代理)。 如果你只希望特定客户端使用服务对象, 这里的对象可以是操作系统中非常重要的部分, 而客户端则是各种已启动的程序 (包括恶意程序), 此时可使用代理模式。
代理可仅在客户端凭据满足要求时将请求传递给服务对象。
本地执行远程服务 (远程代理)。 适用于服务对象位于远程服务器上的情形。
在这种情形中, 代理通过网络传递客户端请求, 负责处理所有与网络相关的复杂细节。
记录日志请求 (日志记录代理)。 适用于当你需要保存对于服务对象的请求历史记录时。 代理可以在向服务传递请求前进行记录。
缓存请求结果 (缓存代理)。 适用于需要缓存客户请求结果并对缓存生命周期进行管理时, 特别是当返回结果的体积非常大时。
- 代理可对重复请求所需的相同结果进行缓存, 还可使用请求参数作为索引缓存的键值。
智能引用。 可在没有客户端使用某个重量级对象时立即销毁该对象。
代理会将所有获取了指向服务对象或其结果的客户端记录在案。 代理会时不时地遍历各个客户端, 检查它们是否仍在运行。 如果相应的客户端列表为空, 代理就会销毁该服务对象, 释放底层系统资源。
代理还可以记录客户端是否修改了服务对象。 其他客户端还可以复用未修改的对象。
- 优缺点
优点
- 你可以在客户端毫无察觉的情况下控制服务对象。
- 如果客户端对服务对象的生命周期没有特殊要求, 你可以对生命周期进行管理。
- 即使服务对象还未准备好或不存在, 代理也可以正常工作。
- 开闭原则。 你可以在不对服务或客户端做出修改的情况下创建新代理。
缺点
- 代码可能会变得复杂, 因为需要新建许多类。
- 服务响应可能会延迟。
- 与其他模式的关系
适配器模式能为被封装对象提供不同的接口, 代理模式能为对象提供相同的接口, 装饰模式则能为对象提供加强的接口。
外观模式与代理的相似之处在于它们都缓存了一个复杂实体并自行对其进行初始化。 代理与其服务对象遵循同一接口, 使得自己和服务对象可以互换, 在这一点上它与外观不同。
装饰和代理有着相似的结构, 但是其意图却非常不同。 这两个模式的构建都基于组合原则, 也就是说一个对象应该将部分工作委派给另一个对象。 两者之间的不同之处在于代理通常自行管理其服务对象的生命周期, 而装饰的生成则总是由客户端进行控制。
3.1 责任链模式
- 问题
假如你正在开发一个在线订购系统。 你希望对系统访问进行限制, 只允许认证用户创建订单。 此外, 拥有管理权限的用户也拥有所有订单的完全访问权限。
简单规划后, 你会意识到这些检查必须依次进行。 只要接收到包含用户凭据的请求, 应用程序就可尝试对进入系统的用户进行认证。 但如果由于用户凭据不正确而导致认证失败, 那就没有必要进行后续检查了。
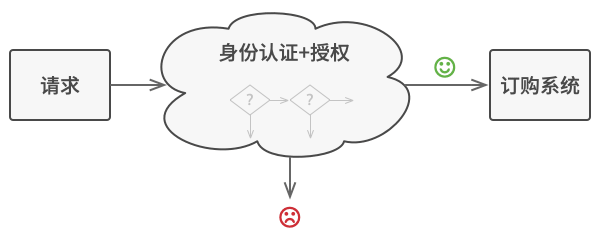
在接下来的几个月里, 你实现了后续的几个检查步骤。
一位同事认为直接将原始数据传递给订购系统存在安全隐患。 因此你新增了额外的验证步骤来清理请求中的数据。
过了一段时间, 有人注意到系统无法抵御暴力密码破解方式的攻击。 为了防范这种情况, 你立刻添加了一个检查步骤来过滤来自同一 IP 地址的重复错误请求。
又有人提议你可以对包含同样数据的重复请求返回缓存中的结果, 从而提高系统响应速度。 因此, 你新增了一个检查步骤, 确保只有没有满足条件的缓存结果时请求才能通过并被发送给系统。
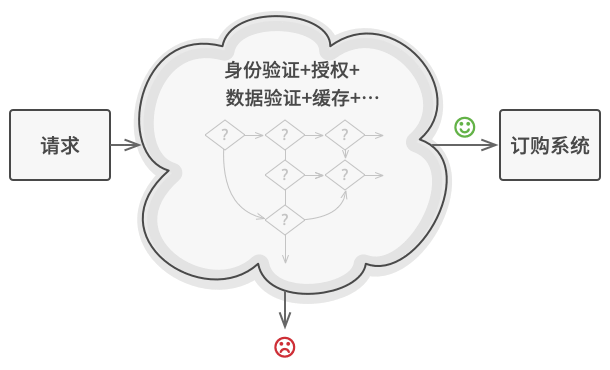
检查代码本来就已经混乱不堪, 而每次新增功能都会使其更加臃肿。 修改某个检查步骤有时会影响其他的检查步骤。 最糟糕的是, 当你希望复用这些检查步骤来保护其他系统组件时, 你只能复制部分代码, 因为这些组件只需部分而非全部的检查步骤。
系统会变得让人非常费解, 而且其维护成本也会激增。 你在艰难地和这些代码共处一段时间后, 有一天终于决定对整个系统进行重构。
- 方案、架构
与许多其他行为设计模式一样, 责任链会将特定行为转换为被称作处理者的独立对象。 在上述示例中, 每个检查步骤都可被抽取为仅有单个方法的类, 并执行检查操作。 请求及其数据则会被作为参数传递给该方法。
模式建议你将这些处理者连成一条链。 链上的每个处理者都有一个成员变量来保存对于下一处理者的引用。 除了处理请求外, 处理者还负责沿着链传递请求。 请求会在链上移动, 直至所有处理者都有机会对其进行处理。
最重要的是: 处理者可以决定不再沿着链传递请求, 这可高效地取消所有后续处理步骤。
在我们的订购系统示例中, 处理者会在进行请求处理工作后决定是否继续沿着链传递请求。 如果请求中包含正确的数据, 所有处理者都将执行自己的主要行为, 无论该行为是身份验证还是数据缓存。
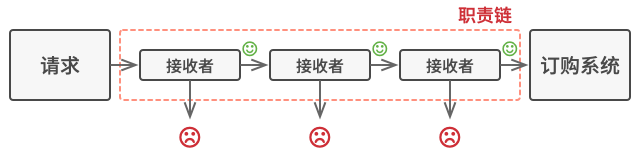
不过还有一种稍微不同的方式 (也是更经典一种), 那就是处理者接收到请求后自行决定是否能够对其进行处理。 如果自己能够处理, 处理者就不再继续传递请求。 因此在这种情况下, 每个请求要么最多有一个处理者对其进行处理, 要么没有任何处理者对其进行处理。 在处理图形用户界面元素栈中的事件时, 这种方式非常常见。
例如, 当用户点击按钮时, 按钮产生的事件将沿着 GUI 元素链进行传递, 最开始是按钮的容器 (如窗体或面板), 直至应用程序主窗口。 链上第一个能处理该事件的元素会对其进行处理。 此外, 该例还有另一个值得我们关注的地方: 它表明我们总能从对象树中抽取出链来。
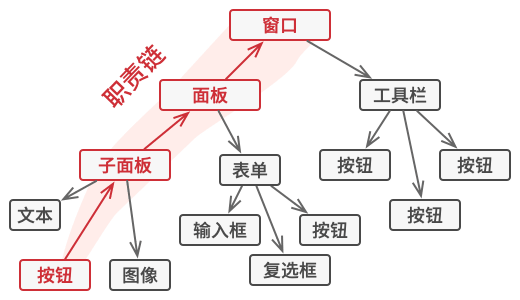
所有处理者类均实现同一接口是关键所在。 每个具体处理者仅关心下一个包含 execute执行方法的处理者。 这样一来, 你就可以在运行时使用不同的处理者来创建链, 而无需将相关代码与处理者的具体类进行耦合。
在本例中, 责任链模式负责为活动的 GUI 元素显示上下文帮助信息。
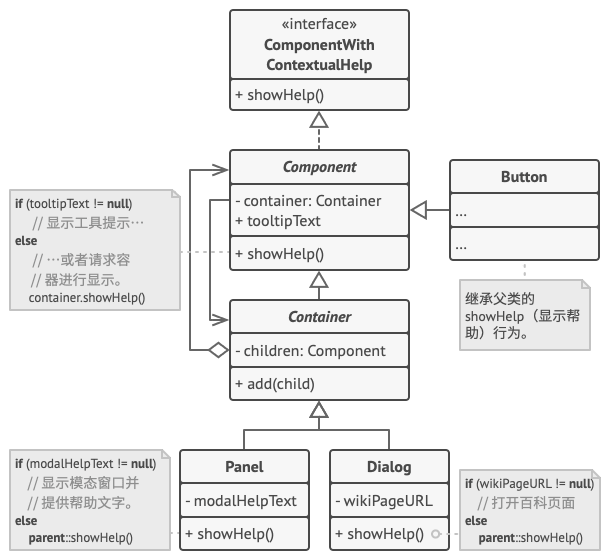
应用程序的 GUI 通常为对象树结构。 例如, 负责渲染程序主窗口的 对话框类就是对象树的根节点。 对话框包含 面板 , 而面板可能包含其他面板, 或是 按钮和 文本框等下层元素。
只要给一个简单的组件指定帮助文本, 它就可显示简短的上下文提示。 但更复杂的组件可自定义上下文帮助文本的显示方式, 例如显示手册摘录内容或在浏览器中打开一个网页。
- 适用场景
当程序需要使用不同方式处理不同种类请求, 而且请求类型和顺序预先未知时, 可以使用责任链模式。
该模式能将多个处理者连接成一条链。 接收到请求后, 它会 “询问” 每个处理者是否能够对其进行处理。 这样所有处理者都有机会来处理请求。
当必须按顺序执行多个处理者时, 可以使用该模式。
无论你以何种顺序将处理者连接成一条链, 所有请求都会严格按照顺序通过链上的处理者。
如果所需处理者及其顺序必须在运行时进行改变, 可以使用责任链模式。
如果在处理者类中有对引用成员变量的设定方法, 你将能动态地插入和移除处理者, 或者改变其顺序。
- 优缺点
优点
- 你可以控制请求处理的顺序。
- 单一职责原则。 你可对发起操作和执行操作的类进行解耦。
- 开闭原则。 你可以在不更改现有代码的情况下在程序中新增处理者。
缺点
部分请求可能未被处理。
- 与其他模式的关系
责任链模式、 命令模式、 中介者模式和观察者模式用于处理请求发送者和接收者之间的不同连接方式:
1.1 责任链按照顺序将请求动态传递给一系列的潜在接收者, 直至其中一名接收者对请求进行处理。
1.2 命令在发送者和请求者之间建立单向连接。
1.3 中介者清除了发送者和请求者之间的直接连接, 强制它们通过一个中介对象进行间接沟通。
1.4 观察者允许接收者动态地订阅或取消接收请求。
责任链通常和组合模式结合使用。 在这种情况下, 叶组件接收到请求后, 可以将请求沿包含全体父组件的链一直传递至对象树的底部。
责任链的管理者可使用命令模式实现。 在这种情况下, 你可以对由请求代表的同一个上下文对象执行许多不同的操作。
还有另外一种实现方式, 那就是请求自身就是一个命令对象。 在这种情况下, 你可以对由一系列不同上下文连接而成的链执行相同的操作。
责任链和装饰模式的类结构非常相似。 两者都依赖递归组合将需要执行的操作传递给一系列对象。 但是, 两者有几点重要的不同之处。
责任链的管理者可以相互独立地执行一切操作, 还可以随时停止传递请求。 另一方面, 各种装饰可以在遵循基本接口的情况下扩展对象的行为。 此外, 装饰无法中断请求的传递。
3.2 命令模式
- 问题
假如你正在开发一款新的文字编辑器, 当前的任务是创建一个包含多个按钮的工具栏, 并让每个按钮对应编辑器的不同操作。 你创建了一个非常简洁的 按钮类, 它不仅可用于生成工具栏上的按钮, 还可用于生成各种对话框的通用按钮。
尽管所有按钮看上去都很相似, 但它们可以完成不同的操作 (打开、 保存、 打印和应用等)。 你会在哪里放置这些按钮的点击处理代码呢? 最简单的解决方案是在使用按钮的每个地方都创建大量的子类。 这些子类中包含按钮点击后必须执行的代码。
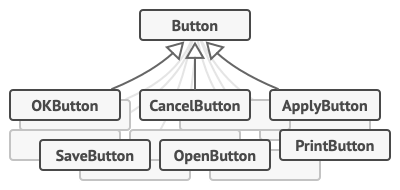
你很快就意识到这种方式有严重缺陷。 首先, 你创建了大量的子类, 当每次修改基类 按钮时, 你都有可能需要修改所有子类的代码。 简单来说, GUI 代码以一种拙劣的方式依赖于业务逻辑中的不稳定代码。

还有一个部分最难办。 复制/粘贴文字等操作可能会在多个地方被调用。 例如用户可以点击工具栏上小小的 “复制” 按钮, 或者通过上下文菜单复制一些内容, 又或者直接使用键盘上的 Ctrl+C 。
我们的程序最初只有工具栏, 因此可以使用按钮子类来实现各种不同操作。 换句话来说, 复制按钮CopyButton子类包含复制文字的代码是可行的。 在实现了上下文菜单、 快捷方式和其他功能后, 你要么需要将操作代码复制进许多个类中, 要么需要让菜单依赖于按钮, 而后者是更糟糕的选择。
- 方案、架构
优秀的软件设计通常会将关注点进行分离, 而这往往会导致软件的分层。 最常见的例子: 一层负责用户图像界面; 另一层负责业务逻辑。 GUI 层负责在屏幕上渲染美观的图形, 捕获所有输入并显示用户和程序工作的结果。 当需要完成一些重要内容时 (比如计算月球轨道或撰写年度报告), GUI 层则会将工作委派给业务逻辑底层。
这在代码中看上去就像这样: 一个 GUI 对象传递一些参数来调用一个业务逻辑对象。 这个过程通常被描述为一个对象发送请求给另一个对象。
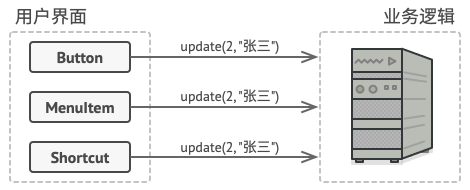
命令模式建议 GUI 对象不直接提交这些请求。 你应该将请求的所有细节 (例如调用的对象、 方法名称和参数列表) 抽取出来组成命令类, 该类中仅包含一个用于触发请求的方法。
命令对象负责连接不同的 GUI 和业务逻辑对象。 此后, GUI 对象无需了解业务逻辑对象是否获得了请求, 也无需了解其对请求进行处理的方式。 GUI 对象触发命令即可, 命令对象会自行处理所有细节工作。

下一步是让所有命令实现相同的接口。 该接口通常只有一个没有任何参数的执行方法, 让你能在不和具体命令类耦合的情况下使用同一请求发送者执行不同命令。 此外还有额外的好处, 现在你能在运行时切换连接至发送者的命令对象, 以此改变发送者的行为。
你可能会注意到遗漏的一块拼图——请求的参数。 GUI 对象可以给业务层对象提供一些参数。 但执行命令方法没有任何参数, 所以我们如何将请求的详情发送给接收者呢? 答案是: 使用数据对命令进行预先配置, 或者让其能够自行获取数据。
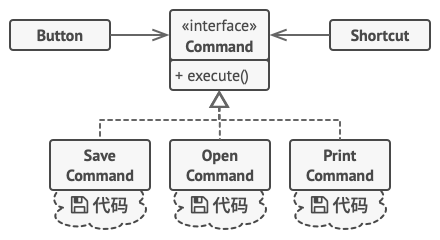
让我们回到文本编辑器。 应用命令模式后, 我们不再需要任何按钮子类来实现点击行为。 我们只需在 按钮Button基类中添加一个成员变量来存储对于命令对象的引用, 并在点击后执行该命令即可。
你需要为每个可能的操作实现一系列命令类, 并且根据按钮所需行为将命令和按钮连接起来。
其他菜单、 快捷方式或整个对话框等 GUI 元素都可以通过相同方式来实现。 当用户与 GUI 元素交互时, 与其连接的命令将会被执行。 现在你很可能已经猜到了, 与相同操作相关的元素将会被连接到相同的命令, 从而避免了重复代码。
最后, 命令成为了减少 GUI 和业务逻辑层之间耦合的中间层。 而这仅仅是命令模式所提供的一小部分好处!
在本例中, 命令模式会记录已执行操作的历史记录, 以在需要时撤销操作。
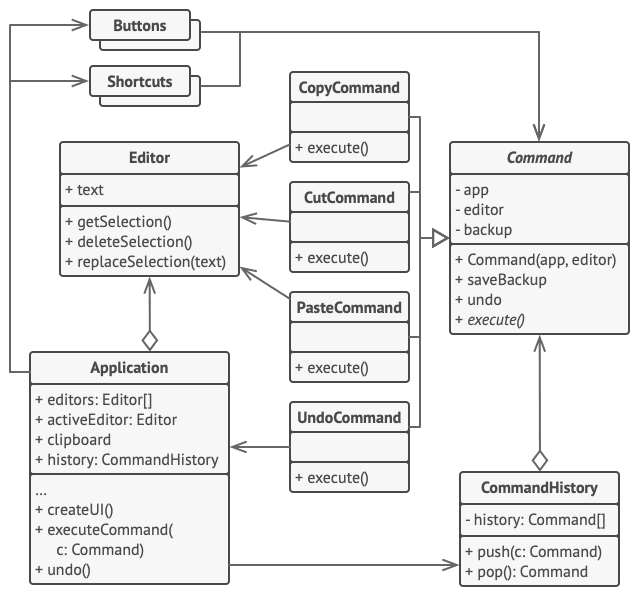
有些命令会改变编辑器的状态 (例如剪切和粘贴), 它们可在执行相关操作前对编辑器的状态进行备份。 命令执行后会和当前点备份的编辑器状态一起被放入命令历史 (命令对象栈)。 此后, 如果用户需要进行回滚操作, 程序可从历史记录中取出最近的命令, 读取相应的编辑器状态备份, 然后进行恢复。
客户端代码 (GUI 元素和命令历史等) 没有和具体命令类相耦合, 因为它通过命令接口来使用命令。 这使得你能在无需修改已有代码的情况下在程序中增加新的命令。
// 命令基类会为所有具体命令定义通用接口。abstract class Command is protected field app: Application protected field editor: Editor protected field backup: text
constructor Command(app: Application, editor: Editor) is this.app = app this.editor = editor
// 备份编辑器状态。 method saveBackup() is backup = editor.text
// 恢复编辑器状态。 method undo() is editor.text = backup
// 执行方法被声明为抽象以强制所有具体命令提供自己的实现。该方法必须根 // 据命令是否更改编辑器的状态返回 true 或 false。 abstract method execute()
// 这里是具体命令。class CopyCommand extends Command is // 复制命令不会被保存到历史记录中,因为它没有改变编辑器的状态。 method execute() is app.clipboard = editor.getSelection() return false
class CutCommand extends Command is // 剪切命令改变了编辑器的状态,因此它必须被保存到历史记录中。只要方法 // 返回 true,它就会被保存。 method execute() is saveBackup() app.clipboard = editor.getSelection() editor.deleteSelection() return true
class PasteCommand extends Command is method execute() is saveBackup() editor.replaceSelection(app.clipboard) return true
// 撤销操作也是一个命令。class UndoCommand extends Command is method execute() is app.undo() return false
// 全局命令历史记录就是一个堆桟。class CommandHistory is private field history: array of Command
// 后进... method push(c: Command) is // 将命令压入历史记录数组的末尾。
// ...先出 method pop():Command is // 从历史记录中取出最近的命令。
// 编辑器类包含实际的文本编辑操作。它会担任接收者的角色:最后所有命令都会// 将执行工作委派给编辑器的方法。class Editor is field text: string
method getSelection() is // 返回选中的文字。
method deleteSelection() is // 删除选中的文字。
method replaceSelection(text) is // 在当前位置插入剪贴板中的内容。
// 应用程序类会设置对象之间的关系。它会担任发送者的角色:当需要完成某些工// 作时,它会创建并执行一个命令对象。class Application is field clipboard: string field editors: array of Editors field activeEditor: Editor field history: CommandHistory
// 将命令分派给 UI 对象的代码可能会是这样的。 method createUI() is // ... copy = function() { executeCommand( new CopyCommand(this, activeEditor)) } copyButton.setCommand(copy) shortcuts.onKeyPress("Ctrl+C", copy)
cut = function() { executeCommand( new CutCommand(this, activeEditor)) } cutButton.setCommand(cut) shortcuts.onKeyPress("Ctrl+X", cut)
paste = function() { executeCommand( new PasteCommand(this, activeEditor)) } pasteButton.setCommand(paste) shortcuts.onKeyPress("Ctrl+V", paste)
undo = function() { executeCommand( new UndoCommand(this, activeEditor)) } undoButton.setCommand(undo) shortcuts.onKeyPress("Ctrl+Z", undo)
// 执行一个命令并检查它是否需要被添加到历史记录中。 method executeCommand(command) is if (command.execute) history.push(command)
// 从历史记录中取出最近的命令并运行其 undo(撤销)方法。请注意,你并 // 不知晓该命令所属的类。但是我们不需要知晓,因为命令自己知道如何撤销 // 其动作。 method undo() is command = history.pop() if (command != null) command.undo()- 适用场景
如果你需要通过操作来参数化对象, 可使用命令模式。
命令模式可将特定的方法调用转化为独立对象。 这一改变也带来了许多有趣的应用: 你可以将命令作为方法的参数进行传递、 将命令保存在其他对象中, 或者在运行时切换已连接的命令等。
举个例子: 你正在开发一个 GUI 组件 (例如上下文菜单), 你希望用户能够配置菜单项, 并在点击菜单项时触发操作。
如果你想要将操作放入队列中、 操作的执行或者远程执行操作, 可使用命令模式。
同其他对象一样, 命令也可以实现序列化 (序列化的意思是转化为字符串), 从而能方便地写入文件或数据库中。 一段时间后, 该字符串可被恢复成为最初的命令对象。 因此, 你可以延迟或计划命令的执行。 但其功能远不止如此! 使用同样的方式, 你还可以将命令放入队列、 记录命令或者通过网络发送命令。
如果你想要实现操作回滚功能, 可使用命令模式。
尽管有很多方法可以实现撤销和恢复功能, 但命令模式可能是其中最常用的一种。
为了能够回滚操作, 你需要实现已执行操作的历史记录功能。 命令历史记录是一种包含所有已执行命令对象及其相关程序状态备份的栈结构。
这种方法有两个缺点。 首先, 程序状态的保存功能并不容易实现, 因为部分状态可能是私有的。 你可以使用备忘录模式来在一定程度上解决这个问题。
其次, 备份状态可能会占用大量内存。 因此, 有时你需要借助另一种实现方式: 命令无需恢复原始状态, 而是执行反向操作。 反向操作也有代价: 它可能会很难甚至是无法实现。
- 优缺点
优点
- 单一职责原则。 你可以解耦触发和执行操作的类。
- 开闭原则。 你可以在不修改已有客户端代码的情况下在程序中创建新的命令。
- 你可以实现撤销和恢复功能。
- 你可以实现操作的延迟执行。
- 你可以将一组简单命令组合成一个复杂命令。
缺点
代码可能会变得更加复杂, 因为你在发送者和接收者之间增加了一个全新的层次。
- 与其他模式的关系
责任链模式、 命令模式、 中介者模式和观察者模式用于处理请求发送者和接收者之间的不同连接方式:
1.1 责任链按照顺序将请求动态传递给一系列的潜在接收者, 直至其中一名接收者对请求进行处理。
1.2 命令在发送者和请求者之间建立单向连接。
1.3 中介者清除了发送者和请求者之间的直接连接, 强制它们通过一个中介对象进行间接沟通。
1.4 观察者允许接收者动态地订阅或取消接收请求。
责任链的管理者可使用命令模式实现。 在这种情况下, 你可以对由请求代表的同一个上下文对象执行许多不同的操作。
还有另外一种实现方式, 那就是请求自身就是一个命令对象。 在这种情况下, 你可以对由一系列不同上下文连接而成的链执行相同的操作。
你可以同时使用命令和备忘录模式来实现 “撤销”。 在这种情况下, 命令用于对目标对象执行各种不同的操作, 备忘录用来保存一条命令执行前该对象的状态。
命令和策略模式看上去很像, 因为两者都能通过某些行为来参数化对象。 但是, 它们的意图有非常大的不同。
4.1 你可以使用命令来将任何操作转换为对象。 操作的参数将成为对象的成员变量。 你可以通过转换来延迟操作的执行、 将操作放入队列、 保存历史命令或者向远程服务发送命令等。
4.2 另一方面, 策略通常可用于描述完成某件事的不同方式, 让你能够在同一个上下文类中切换算法。
原型模式可用于保存命令的历史记录。
你可以将访问者模式视为命令模式的加强版本, 其对象可对不同类的多种对象执行操作。
3.3 迭代器模式
- 问题
集合是编程中最常使用的数据类型之一。 尽管如此, 集合只是一组对象的容器而已。
大部分集合使用简单列表存储元素。 但有些集合还会使用栈、 树、 图和其他复杂的数据结构。
无论集合的构成方式如何, 它都必须提供某种访问元素的方式, 便于其他代码使用其中的元素。 集合应提供一种能够遍历元素的方式, 且保证它不会周而复始地访问同一个元素。
如果你的集合基于列表, 那么这项工作听上去仿佛很简单。 但如何遍历复杂数据结构 (例如树) 中的元素呢? 例如, 今天你需要使用深度优先算法来遍历树结构, 明天可能会需要广度优先算法; 下周则可能会需要其他方式 (比如随机存取树中的元素)。
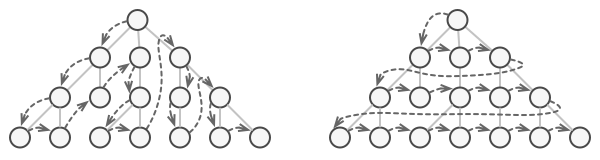
不断向集合中添加遍历算法会模糊其 “高效存储数据” 的主要职责。 此外, 有些算法可能是根据特定应用订制的, 将其加入泛型集合类中会显得非常奇怪。
另一方面, 使用多种集合的客户端代码可能并不关心存储数据的方式。 不过由于集合提供不同的元素访问方式, 你的代码将不得不与特定集合类进行耦合。
- 方案、架构
迭代器模式的主要思想是将集合的遍历行为抽取为单独的迭代器对象。
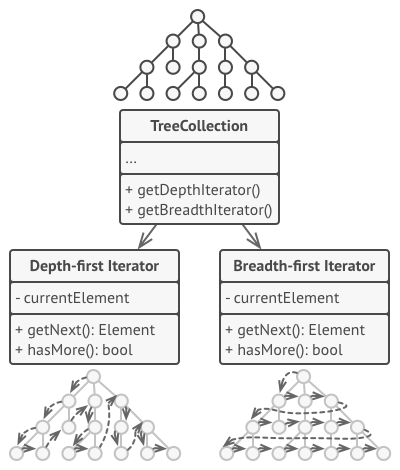
除实现自身算法外, 迭代器还封装了遍历操作的所有细节, 例如当前位置和末尾剩余元素的数量。 因此, 多个迭代器可以在相互独立的情况下同时访问集合。
迭代器通常会提供一个获取集合元素的基本方法。 客户端可不断调用该方法直至它不返回任何内容, 这意味着迭代器已经遍历了所有元素。
所有迭代器必须实现相同的接口。 这样一来, 只要有合适的迭代器, 客户端代码就能兼容任何类型的集合或遍历算法。 如果你需要采用特殊方式来遍历集合, 只需创建一个新的迭代器类即可, 无需对集合或客户端进行修改。
在本例中, 迭代器模式用于遍历一个封装了访问微信好友关系功能的特殊集合。 该集合提供使用不同方式遍历档案资料的多个迭代器。
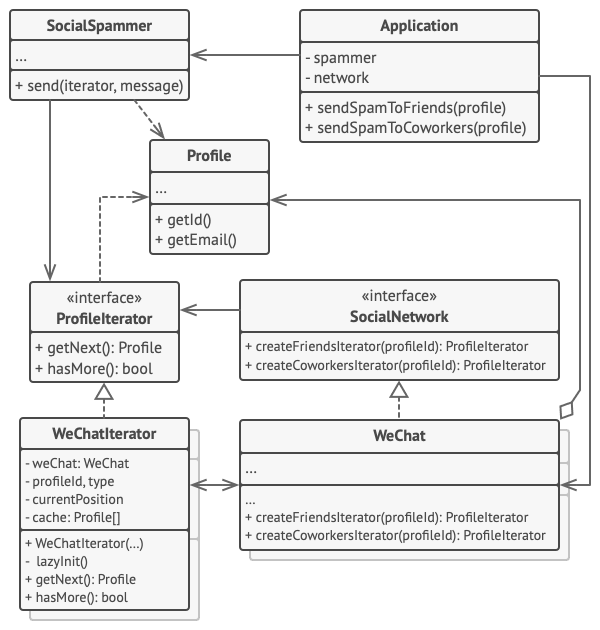
“好友 (friends)” 迭代器可用于遍历指定档案的好友。 “同事 (colleagues)” 迭代器也提供同样的功能, 但仅包括与目标用户在同一家公司工作的好友。 这两个迭代器都实现了同一个通用接口, 客户端能在不了解认证和发送 REST 请求等实现细节的情况下获取档案。
客户端仅通过接口与集合和迭代器交互, 也就不会同具体类耦合。 如果你决定将应用连接到全新的社交网络, 只需提供新的集合和迭代器类即可, 无需修改现有代码。
- 适用场景
当集合背后为复杂的数据结构, 且你希望对客户端隐藏其复杂性时 (出于使用便利性或安全性的考虑), 可以使用迭代器模式。
迭代器封装了与复杂数据结构进行交互的细节, 为客户端提供多个访问集合元素的简单方法。 这种方式不仅对客户端来说非常方便, 而且能避免客户端在直接与集合交互时执行错误或有害的操作, 从而起到保护集合的作用。
使用该模式可以减少程序中重复的遍历代码。
重要迭代算法的代码往往体积非常庞大。 当这些代码被放置在程序业务逻辑中时, 它会让原始代码的职责模糊不清, 降低其可维护性。 因此, 将遍历代码移到特定的迭代器中可使程序代码更加精炼和简洁。
如果你希望代码能够遍历不同的甚至是无法预知的数据结构, 可以使用迭代器模式。
该模式为集合和迭代器提供了一些通用接口。 如果你在代码中使用了这些接口, 那么将其他实现了这些接口的集合和迭代器传递给它时, 它仍将可以正常运行。
- 优缺点
优点
- 单一职责原则。 通过将体积庞大的遍历算法代码抽取为独立的类, 你可对客户端代码和集合进行整理。
- 开闭原则。 你可实现新型的集合和迭代器并将其传递给现有代码, 无需修改现有代码。
- 你可以并行遍历同一集合, 因为每个迭代器对象都包含其自身的遍历状态。
- 相似的, 你可以暂停遍历并在需要时继续。
缺点
- 如果你的程序只与简单的集合进行交互, 应用该模式可能会矫枉过正。
- 对于某些特殊集合, 使用迭代器可能比直接遍历的效率低。
- 与其他模式的关系
你可以使用迭代器模式来遍历组合模式树。
你可以同时使用工厂方法模式和迭代器来让子类集合返回不同类型的迭代器, 并使得迭代器与集合相匹配。
你可以同时使用备忘录模式和迭代器来获取当前迭代器的状态, 并且在需要的时候进行回滚。
可以同时使用访问者模式和迭代器来遍历复杂数据结构, 并对其中的元素执行所需操作, 即使这些元素所属的类完全不同。
3.4 中介者模式
- 问题
假如你有一个创建和修改客户资料的对话框, 它由各种控件组成, 例如文本框 (TextField)、 复选框 (Checkbox) 和按钮 (Button) 等。
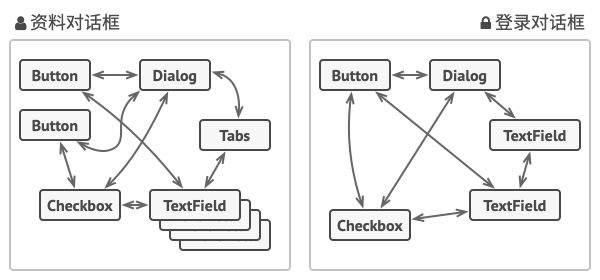
某些表单元素可能会直接进行互动。 例如, 选中 “我有一只狗” 复选框后可能会显示一个隐藏文本框用于输入狗狗的名字。 另一个例子是提交按钮必须在保存数据前校验所有输入内容。
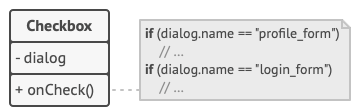
如果直接在表单元素代码中实现业务逻辑, 你将很难在程序其他表单中复用这些元素类。 例如, 由于复选框类与狗狗的文本框相耦合, 所以将无法在其他表单中使用它。 你要么使用渲染资料表单时用到的所有类, 要么一个都不用。
- 方案、架构
中介者模式建议你停止组件之间的直接交流并使其相互独立。 这些组件必须调用特殊的中介者对象, 通过中介者对象重定向调用行为, 以间接的方式进行合作。 最终, 组件仅依赖于一个中介者类, 无需与多个其他组件相耦合。
在资料编辑表单的例子中, 对话框 (Dialog) 类本身将作为中介者, 其很可能已知自己所有的子元素, 因此你甚至无需在该类中引入新的依赖关系。
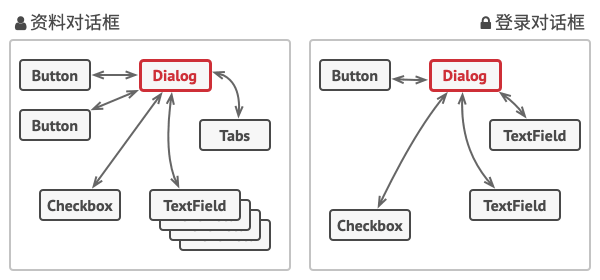
绝大部分重要的修改都在实际表单元素中进行。 让我们想想提交按钮。 之前, 当用户点击按钮后, 它必须对所有表单元素数值进行校验。 而现在它的唯一工作是将点击事件通知给对话框。 收到通知后, 对话框可以自行校验数值或将任务委派给各元素。 这样一来, 按钮不再与多个表单元素相关联, 而仅依赖于对话框类。
你还可以为所有类型的对话框抽取通用接口, 进一步削弱其依赖性。 接口中将声明一个所有表单元素都能使用的通知方法, 可用于将元素中发生的事件通知给对话框。 这样一来, 所有实现了该接口的对话框都能使用这个提交按钮了。
采用这种方式, 中介者模式让你能在单个中介者对象中封装多个对象间的复杂关系网。 类所拥有的依赖关系越少, 就越易于修改、 扩展或复用。
在本例中, 中介者模式可帮助你减少各种 UI 类 (按钮、 复选框和文本标签) 之间的相互依赖关系。
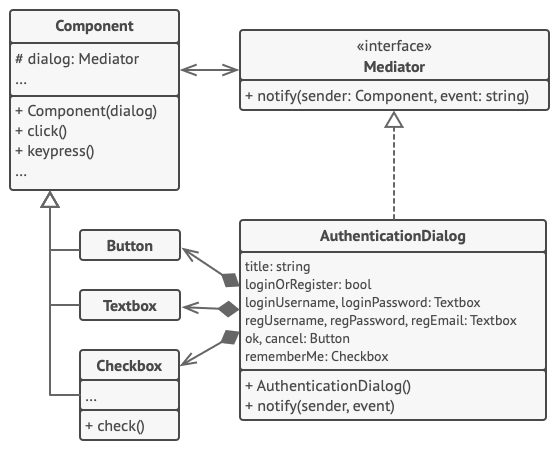
用户触发的元素不会直接与其他元素交流, 即使看上去它们应该这样做。 相反, 元素只需让中介者知晓事件即可, 并能在发出通知时同时传递任何上下文信息。
本例中的中介者是整个认证对话框。 对话框知道具体元素应如何进行合作并促进它们的间接交流。 当接收到事件通知后, 对话框会确定负责处理事件的元素并据此重定向请求。
- 适用场景
当一些对象和其他对象紧密耦合以致难以对其进行修改时, 可使用中介者模式。
该模式让你将对象间的所有关系抽取成为一个单独的类, 以使对于特定组件的修改工作独立于其他组件。
当组件因过于依赖其他组件而无法在不同应用中复用时, 可使用中介者模式。
应用中介者模式后, 每个组件不再知晓其他组件的情况。 尽管这些组件无法直接交流, 但它们仍可通过中介者对象进行间接交流。 如果你希望在不同应用中复用一个组件, 则需要为其提供一个新的中介者类。
如果为了能在不同情景下复用一些基本行为, 导致你需要被迫创建大量组件子类时, 可使用中介者模式。
由于所有组件间关系都被包含在中介者中, 因此你无需修改组件就能方便地新建中介者类以定义新的组件合作方式。
- 优缺点
优点
- 单一职责原则。 你可以将多个组件间的交流抽取到同一位置, 使其更易于理解和维护。
- 开闭原则。 你无需修改实际组件就能增加新的中介者。
- 你可以减轻应用中多个组件间的耦合情况。
- 你可以更方便地复用各个组件。
缺点
一段时间后, 中介者可能会演化成为上帝对象。
- 与其他模式的关系
责任链模式、 命令模式、 中介者模式和观察者模式用于处理请求发送者和接收者之间的不同连接方式:
1.1 责任链按照顺序将请求动态传递给一系列的潜在接收者, 直至其中一名接收者对请求进行处理。
1.2 命令在发送者和请求者之间建立单向连接。
1.3 中介者清除了发送者和请求者之间的直接连接, 强制它们通过一个中介对象进行间接沟通。
1.4 观察者允许接收者动态地订阅或取消接收请求。
外观模式和中介者的职责类似: 它们都尝试在大量紧密耦合的类中组织起合作。
2.1 外观为子系统中的所有对象定义了一个简单接口, 但是它不提供任何新功能。 子系统本身不会意识到外观的存在。 子系统中的对象可以直接进行交流。
2.2 中介者将系统中组件的沟通行为中心化。 各组件只知道中介者对象, 无法直接相互交流。
中介者和观察者之间的区别往往很难记住。 在大部分情况下, 你可以使用其中一种模式, 而有时可以同时使用。 让我们来看看如何做到这一点。
中介者的主要目标是消除一系列系统组件之间的相互依赖。 这些组件将依赖于同一个中介者对象。 观察者的目标是在对象之间建立动态的单向连接, 使得部分对象可作为其他对象的附属发挥作用。
有一种流行的中介者模式实现方式依赖于观察者。 中介者对象担当发布者的角色, 其他组件则作为订阅者, 可以订阅中介者的事件或取消订阅。 当中介者以这种方式实现时, 它可能看上去与观察者非常相似。
当你感到疑惑时, 记住可以采用其他方式来实现中介者。 例如, 你可永久性地将所有组件链接到同一个中介者对象。 这种实现方式和观察者并不相同, 但这仍是一种中介者模式。
假设有一个程序, 其所有的组件都变成了发布者, 它们之间可以相互建立动态连接。 这样程序中就没有中心化的中介者对象, 而只有一些分布式的观察者。
3.5 备忘录模式
- 问题
假如你正在开发一款文字编辑器应用程序。 除了简单的文字编辑功能外, 编辑器中还要有设置文本格式和插入内嵌图片等功能。
后来, 你决定让用户能撤销施加在文本上的任何操作。 这项功能在过去几年里变得十分普遍, 因此用户期待任何程序都有这项功能。 你选择采用直接的方式来实现该功能: 程序在执行任何操作前会记录所有的对象状态, 并将其保存下来。 当用户此后需要撤销某个操作时, 程序将从历史记录中获取最近的快照, 然后使用它来恢复所有对象的状态。
让我们来思考一下这些状态快照。 首先, 到底该如何生成一个快照呢? 很可能你会需要遍历对象的所有成员变量并将其数值复制保存。 但只有当对象对其内容没有严格访问权限限制的情况下, 你才能使用该方式。 不过很遗憾, 绝大部分对象会使用私有成员变量来存储重要数据, 这样别人就无法轻易查看其中的内容。
现在我们暂时忽略这个问题, 假设对象都像嬉皮士一样: 喜欢开放式的关系并会公开其所有状态。 尽管这种方式能够解决当前问题, 让你可随时生成对象的状态快照, 但这种方式仍存在一些严重问题。 未来你可能会添加或删除一些成员变量。 这听上去很简单, 但需要对负责复制受影响对象状态的类进行更改。

还有更多问题。 让我们来考虑编辑器 (Editor) 状态的实际 “快照”, 它需要包含哪些数据? 至少必须包含实际的文本、 光标坐标和当前滚动条位置等。 你需要收集这些数据并将其放入特定容器中, 才能生成快照。
你很可能会将大量的容器对象存储在历史记录列表中。 这样一来, 容器最终大概率会成为同一个类的对象。 这个类中几乎没有任何方法, 但有许多与编辑器状态一一对应的成员变量。 为了让其他对象能保存或读取快照, 你很可能需要将快照的成员变量设为公有。 无论这些状态是否私有, 其都将暴露一切编辑器状态。 其他类会对快照类的每个小改动产生依赖, 除非这些改动仅存在于私有成员变量或方法中, 而不会影响外部类。
我们似乎走进了一条死胡同: 要么会暴露类的所有内部细节而使其过于脆弱; 要么会限制对其状态的访问权限而无法生成快照。 那么, 我们还有其他方式来实现 “撤销” 功能吗?
- 方案、架构
我们刚才遇到的所有问题都是封装 “破损” 造成的。 一些对象试图超出其职责范围的工作。 由于在执行某些行为时需要获取数据, 所以它们侵入了其他对象的私有空间, 而不是让这些对象来完成实际的工作。
备忘录模式将创建状态快照 (Snapshot) 的工作委派给实际状态的拥有者原发器 (Originator) 对象。 这样其他对象就不再需要从 “外部” 复制编辑器状态了, 编辑器类拥有其状态的完全访问权, 因此可以自行生成快照。
模式建议将对象状态的副本存储在一个名为备忘录 (Memento) 的特殊对象中。 除了创建备忘录的对象外, 任何对象都不能访问备忘录的内容。 其他对象必须使用受限接口与备忘录进行交互, 它们可以获取快照的元数据 (创建时间和操作名称等), 但不能获取快照中原始对象的状态。
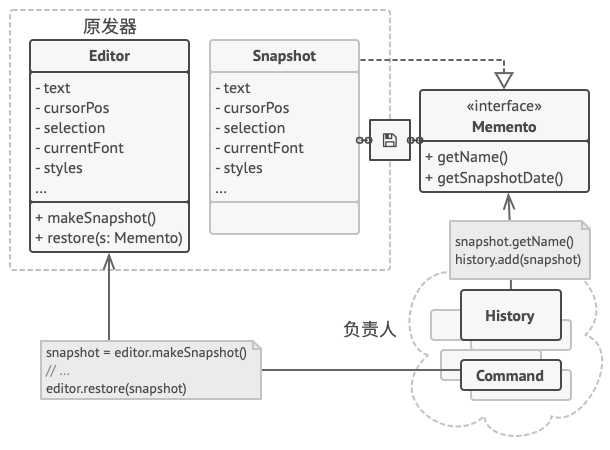
这种限制策略允许你将备忘录保存在通常被称为负责人 (Caretakers) 的对象中。 由于负责人仅通过受限接口与备忘录互动, 故其无法修改存储在备忘录内部的状态。 同时, 原发器拥有对备忘录所有成员的访问权限, 从而能随时恢复其以前的状态。
在文字编辑器的示例中, 我们可以创建一个独立的历史 (History) 类作为负责人。 编辑器每次执行操作前, 存储在负责人中的备忘录栈都会生长。 你甚至可以在应用的 UI 中渲染该栈, 为用户显示之前的操作历史。
当用户触发撤销操作时, 历史类将从栈中取回最近的备忘录, 并将其传递给编辑器以请求进行回滚。 由于编辑器拥有对备忘录的完全访问权限, 因此它可以使用从备忘录中获取的数值来替换自身的状态。
本例结合使用了命令模式与备忘录模式, 可保存复杂文字编辑器的状态快照, 并能在需要时从快照中恢复之前的状态。

命令 (command) 对象将作为负责人, 它们会在执行与命令相关的操作前获取编辑器的备忘录。 当用户试图撤销最近的命令时, 编辑器可以使用保存在命令中的备忘录来将自身回滚到之前的状态。
备忘录类没有声明任何公有的成员变量、 获取器 (getter) 和设置器, 因此没有对象可以修改其内容。 备忘录与创建自己的编辑器相连接, 这使得备忘录能够通过编辑器对象的设置器传递数据, 恢复与其相连接的编辑器的状态。 由于备忘录与特定的编辑器对象相连接, 程序可以使用中心化的撤销栈实现对多个独立编辑器窗口的支持。
- 适用场景
当你需要创建对象状态快照来恢复其之前的状态时, 可以使用备忘录模式。
备忘录模式允许你复制对象中的全部状态 (包括私有成员变量), 并将其独立于对象进行保存。 尽管大部分人因为 “撤销” 这个用例才记得该模式, 但其实它在处理事务 (比如需要在出现错误时回滚一个操作) 的过程中也必不可少。
当直接访问对象的成员变量、 获取器或设置器将导致封装被突破时, 可以使用该模式。
备忘录让对象自行负责创建其状态的快照。 任何其他对象都不能读取快照, 这有效地保障了数据的安全性。
- 优缺点
优点
- 你可以在不破坏对象封装情况的前提下创建对象状态快照。
- 你可以通过让负责人维护原发器状态历史记录来简化原发器代码。
缺点
- 如果客户端过于频繁地创建备忘录, 程序将消耗大量内存。
- 负责人必须完整跟踪原发器的生命周期, 这样才能销毁弃用的备忘录。
- 绝大部分动态编程语言 (例如 PHP、 Python 和 JavaScript) 不能确保备忘录中的状态不被修改。
- 与其他模式的关系
你可以同时使用命令模式和备忘录模式来实现 “撤销”。 在这种情况下, 命令用于对目标对象执行各种不同的操作, 备忘录用来保存一条命令执行前该对象的状态。
你可以同时使用备忘录和迭代器模式来获取当前迭代器的状态, 并且在需要的时候进行回滚。
有时候原型模式可以作为备忘录的一个简化版本, 其条件是你需要在历史记录中存储的对象的状态比较简单, 不需要链接其他外部资源, 或者链接可以方便地重建。
3.6 观察者模式
- 问题
假如你有两种类型的对象: 顾客和 商店 。 顾客对某个特定品牌的产品非常感兴趣 (例如最新型号的 iPhone 手机), 而该产品很快将会在商店里出售。
顾客可以每天来商店看看产品是否到货。 但如果商品尚未到货时, 绝大多数来到商店的顾客都会空手而归。
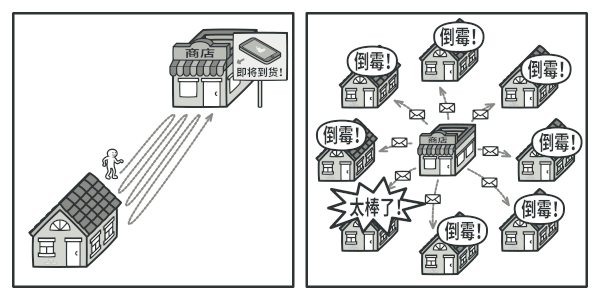
另一方面, 每次新产品到货时, 商店可以向所有顾客发送邮件 (可能会被视为垃圾邮件)。 这样, 部分顾客就无需反复前往商店了, 但也可能会惹恼对新产品没有兴趣的其他顾客。
我们似乎遇到了一个矛盾: 要么让顾客浪费时间检查产品是否到货, 要么让商店浪费资源去通知没有需求的顾客。
- 方案、架构
拥有一些值得关注的状态的对象通常被称为目标, 由于它要将自身的状态改变通知给其他对象, 我们也将其称为发布者 (publisher)。 所有希望关注发布者状态变化的其他对象被称为订阅者 (subscribers)。
观察者模式建议你为发布者类添加订阅机制, 让每个对象都能订阅或取消订阅发布者事件流。 不要害怕! 这并不像听上去那么复杂。 实际上, 该机制包括 1) 一个用于存储订阅者对象引用的列表成员变量; 2) 几个用于添加或删除该列表中订阅者的公有方法。

现在, 无论何时发生了重要的发布者事件, 它都要遍历订阅者并调用其对象的特定通知方法。
实际应用中可能会有十几个不同的订阅者类跟踪着同一个发布者类的事件, 你不会希望发布者与所有这些类相耦合的。 此外如果他人会使用发布者类, 那么你甚至可能会对其中的一些类一无所知。
因此, 所有订阅者都必须实现同样的接口, 发布者仅通过该接口与订阅者交互。 接口中必须声明通知方法及其参数, 这样发布者在发出通知时还能传递一些上下文数据。
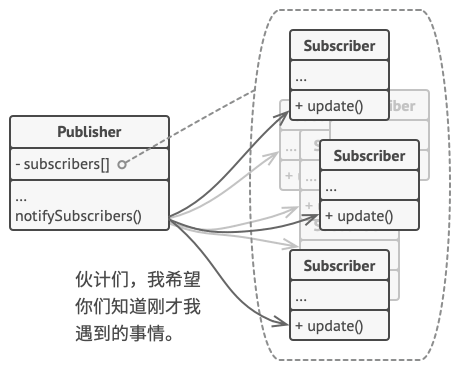
如果你的应用中有多个不同类型的发布者, 且希望订阅者可兼容所有发布者, 那么你甚至可以进一步让所有订阅者遵循同样的接口。 该接口仅需描述几个订阅方法即可。 这样订阅者就能在不与具体发布者类耦合的情况下通过接口观察发布者的状态。
在本例中, 观察者模式允许文本编辑器对象将自身的状态改变通知给其他服务对象。
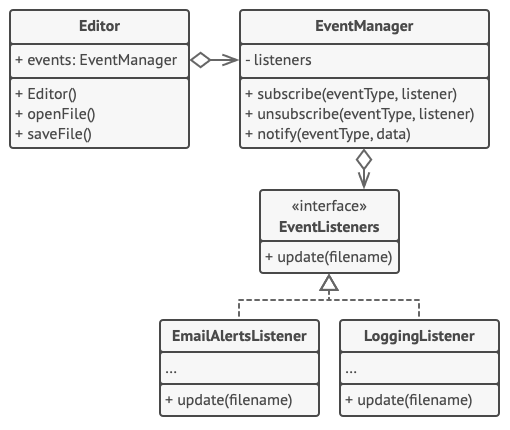
订阅者列表是动态生成的: 对象可在运行时根据程序需要开始或停止监听通知。
在本实现中, 编辑器类自身并不维护订阅列表。 它将工作委派给专门从事此工作的一个特殊帮手对象。 你还可将该对象升级为中心化的事件分发器, 允许任何对象成为发布者。
只要发布者通过同样的接口与所有订阅者进行交互, 那么在程序中新增订阅者时就无需修改已有发布者类的代码。
- 适用场景
当一个对象状态的改变需要改变其他对象, 或实际对象是事先未知的或动态变化的时, 可使用观察者模式。
当你使用图形用户界面类时通常会遇到一个问题。 比如, 你创建了自定义按钮类并允许客户端在按钮中注入自定义代码, 这样当用户按下按钮时就会触发这些代码。
观察者模式允许任何实现了订阅者接口的对象订阅发布者对象的事件通知。 你可在按钮中添加订阅机制, 允许客户端通过自定义订阅类注入自定义代码。
当应用中的一些对象必须观察其他对象时, 可使用该模式。 但仅能在有限时间内或特定情况下使用。
订阅列表是动态的, 因此订阅者可随时加入或离开该列表。
- 优缺点
优点
- 开闭原则。 你无需修改发布者代码就能引入新的订阅者类 (如果是发布者接口则可轻松引入发布者类)。
- 你可以在运行时建立对象之间的联系。
缺点
订阅者的通知顺序是随机的。
- 与其他模式的关系
责任链模式、 命令模式、 中介者模式和观察者模式用于处理请求发送者和接收者之间的不同连接方式:
1.1 责任链按照顺序将请求动态传递给一系列的潜在接收者, 直至其中一名接收者对请求进行处理。
1.2 命令在发送者和请求者之间建立单向连接。
1.3 中介者清除了发送者和请求者之间的直接连接, 强制它们通过一个中介对象进行间接沟通。
1.4 观察者允许接收者动态地订阅或取消接收请求。
中介者和观察者之间的区别往往很难记住。 在大部分情况下, 你可以使用其中一种模式, 而有时可以同时使用。 让我们来看看如何做到这一点。
中介者的主要目标是消除一系列系统组件之间的相互依赖。 这些组件将依赖于同一个中介者对象。 观察者的目标是在对象之间建立动态的单向连接, 使得部分对象可作为其他对象的附属发挥作用。
有一种流行的中介者模式实现方式依赖于观察者。 中介者对象担当发布者的角色, 其他组件则作为订阅者, 可以订阅中介者的事件或取消订阅。 当中介者以这种方式实现时, 它可能看上去与观察者非常相似。
当你感到疑惑时, 记住可以采用其他方式来实现中介者。 例如, 你可永久性地将所有组件链接到同一个中介者对象。 这种实现方式和观察者并不相同, 但这仍是一种中介者模式。
假设有一个程序, 其所有的组件都变成了发布者, 它们之间可以相互建立动态连接。 这样程序中就没有中心化的中介者对象, 而只有一些分布式的观察者。
3.7 状态模式
- 问题
状态模式与有限状态机的概念紧密相关。
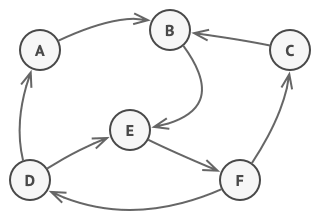
其主要思想是程序在任意时刻仅可处于几种有限的状态中。 在任何一个特定状态中, 程序的行为都不相同, 且可瞬间从一个状态切换到另一个状态。 不过, 根据当前状态, 程序可能会切换到另外一种状态, 也可能会保持当前状态不变。 这些数量有限且预先定义的状态切换规则被称为转移。
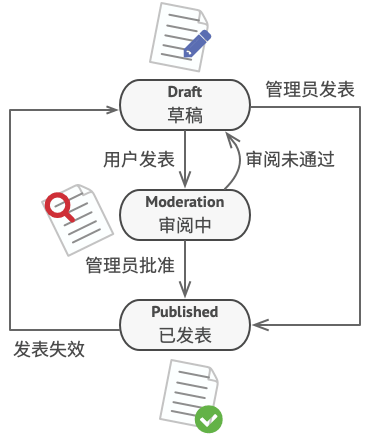
你还可将该方法应用在对象上。 假如你有一个 文档Document类。 文档可能会处于 草稿Draft 、 审阅中Moderation和 已发布Published三种状态中的一种。 文档的 publish发布方法在不同状态下的行为略有不同:
- 处于 草稿状态时, 它会将文档转移到审阅中状态。
- 处于 审阅中状态时, 如果当前用户是管理员, 它会公开发布文档。
- 处于 已发布状态时, 它不会进行任何操作。
状态机通常由众多条件运算符 ( if或 switch ) 实现, 可根据对象的当前状态选择相应的行为。 “状态” 通常只是对象中的一组成员变量值。 即使你之前从未听说过有限状态机, 你也很可能已经实现过状态模式。 下面的代码应该能帮助你回忆起来。
class Document is field state: string // ... method publish() is switch (state) "draft": state = "moderation" break "moderation": if (currentUser.role == 'admin') state = "published" break "published": // 什么也不做。 break // ...当我们逐步在 文档类中添加更多状态和依赖于状态的行为后, 基于条件语句的状态机就会暴露其最大的弱点。 为了能根据当前状态选择完成相应行为的方法, 绝大部分方法中会包含复杂的条件语句。 修改其转换逻辑可能会涉及到修改所有方法中的状态条件语句, 导致代码的维护工作非常艰难。
这个问题会随着项目进行变得越发严重。 我们很难在设计阶段预测到所有可能的状态和转换。 随着时间推移, 最初仅包含有限条件语句的简洁状态机可能会变成臃肿的一团乱麻。
- 方案、架构
状态模式建议为对象的所有可能状态新建一个类, 然后将所有状态的对应行为抽取到这些类中。
原始对象被称为上下文 (context), 它并不会自行实现所有行为, 而是会保存一个指向表示当前状态的状态对象的引用, 且将所有与状态相关的工作委派给该对象。
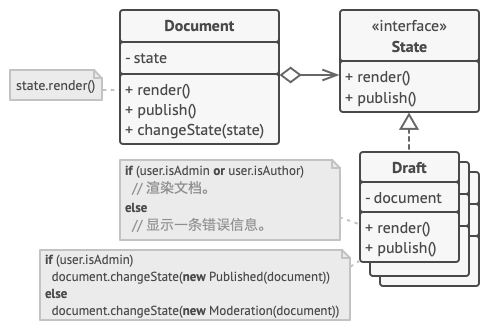
如需将上下文转换为另外一种状态, 则需将当前活动的状态对象替换为另外一个代表新状态的对象。 采用这种方式是有前提的: 所有状态类都必须遵循同样的接口, 而且上下文必须仅通过接口与这些对象进行交互。
这个结构可能看上去与策略模式相似, 但有一个关键性的不同——在状态模式中, 特定状态知道其他所有状态的存在, 且能触发从一个状态到另一个状态的转换; 策略则几乎完全不知道其他策略的存在。
在本例中, 状态模式将根据当前回放状态, 让媒体播放器中的相同控件完成不同的行为。
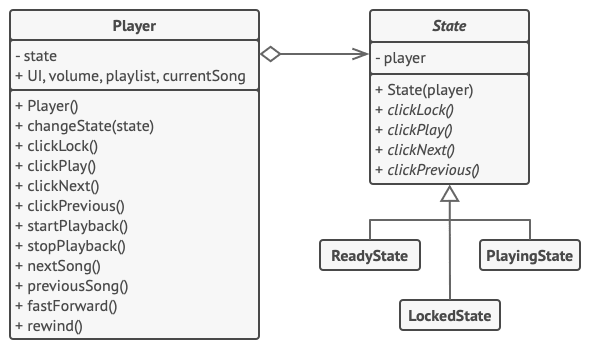
播放器的主要对象总是会连接到一个负责播放器绝大部分工作的状态对象中。 部分操作会更换播放器当前的状态对象, 以此改变播放器对于用户互动所作出的反应。
// 音频播放器(AudioPlayer)类即为上下文。它还会维护指向状态类实例的引用,// 该状态类则用于表示音频播放器当前的状态。class AudioPlayer is field state: State field UI, volume, playlist, currentSong
constructor AudioPlayer() is this.state = new ReadyState(this)
// 上下文会将处理用户输入的工作委派给状态对象。由于每个状态都以不 // 同的方式处理输入,其结果自然将依赖于当前所处的状态。 UI = new UserInterface() UI.lockButton.onClick(this.clickLock) UI.playButton.onClick(this.clickPlay) UI.nextButton.onClick(this.clickNext) UI.prevButton.onClick(this.clickPrevious)
// 其他对象必须能切换音频播放器当前所处的状态。 method changeState(state: State) is this.state = state
// UI 方法会将执行工作委派给当前状态。 method clickLock() is state.clickLock() method clickPlay() is state.clickPlay() method clickNext() is state.clickNext() method clickPrevious() is state.clickPrevious()
// 状态可调用上下文的一些服务方法。 method startPlayback() is // ... method stopPlayback() is // ... method nextSong() is // ... method previousSong() is // ... method fastForward(time) is // ... method rewind(time) is // ...
// 所有具体状态类都必须实现状态基类声明的方法,并提供反向引用指向与状态相// 关的上下文对象。状态可使用反向引用将上下文转换为另一个状态。abstract class State is protected field player: AudioPlayer
// 上下文将自身传递给状态构造函数。这可帮助状态在需要时获取一些有用的 // 上下文数据。 constructor State(player) is this.player = player
abstract method clickLock() abstract method clickPlay() abstract method clickNext() abstract method clickPrevious()
// 具体状态会实现与上下文状态相关的多种行为。class LockedState extends State is
// 当你解锁一个锁定的播放器时,它可能处于两种状态之一。 method clickLock() is if (player.playing) player.changeState(new PlayingState(player)) else player.changeState(new ReadyState(player))
method clickPlay() is // 已锁定,什么也不做。
method clickNext() is // 已锁定,什么也不做。
method clickPrevious() is // 已锁定,什么也不做。
// 它们还可在上下文中触发状态转换。class ReadyState extends State is method clickLock() is player.changeState(new LockedState(player))
method clickPlay() is player.startPlayback() player.changeState(new PlayingState(player))
method clickNext() is player.nextSong()
method clickPrevious() is player.previousSong()
class PlayingState extends State is method clickLock() is player.changeState(new LockedState(player))
method clickPlay() is player.stopPlayback() player.changeState(new ReadyState(player))
method clickNext() is if (event.doubleclick) player.nextSong() else player.fastForward(5)
method clickPrevious() is if (event.doubleclick) player.previous() else player.rewind(5)- 适用场景
如果对象需要根据自身当前状态进行不同行为, 同时状态的数量非常多且与状态相关的代码会频繁变更的话, 可使用状态模式。
模式建议你将所有特定于状态的代码抽取到一组独立的类中。 这样一来, 你可以在独立于其他状态的情况下添加新状态或修改已有状态, 从而减少维护成本。
如果某个类需要根据成员变量的当前值改变自身行为, 从而需要使用大量的条件语句时, 可使用该模式。
状态模式会将这些条件语句的分支抽取到相应状态类的方法中。 同时, 你还可以清除主要类中与特定状态相关的临时成员变量和帮手方法代码。
当相似状态和基于条件的状态机转换中存在许多重复代码时, 可使用状态模式。
状态模式让你能够生成状态类层次结构, 通过将公用代码抽取到抽象基类中来减少重复。
- 优缺点
优点
- 单一职责原则。 将与特定状态相关的代码放在单独的类中。
- 开闭原则。 无需修改已有状态类和上下文就能引入新状态。
- 通过消除臃肿的状态机条件语句简化上下文代码。
缺点
如果状态机只有很少的几个状态, 或者很少发生改变, 那么应用该模式可能会显得小题大作。
- 与其他模式的关系
桥接模式、 状态模式和策略模式 (在某种程度上包括适配器模式) 模式的接口非常相似。 实际上, 它们都基于组合模式——即将工作委派给其他对象, 不过也各自解决了不同的问题。 模式并不只是以特定方式组织代码的配方, 你还可以使用它们来和其他开发者讨论模式所解决的问题。
状态可被视为策略的扩展。 两者都基于组合机制: 它们都通过将部分工作委派给 “帮手” 对象来改变其在不同情景下的行为。 策略使得这些对象相互之间完全独立, 它们不知道其他对象的存在。 但状态模式没有限制具体状态之间的依赖, 且允许它们自行改变在不同情景下的状态。
3.8 策略模式
- 问题
一天, 你打算为游客们创建一款导游程序。 该程序的核心功能是提供美观的地图, 以帮助用户在任何城市中快速定位。
用户期待的程序新功能是自动路线规划: 他们希望输入地址后就能在地图上看到前往目的地的最快路线。
程序的首个版本只能规划公路路线。 驾车旅行的人们对此非常满意。 但很显然, 并非所有人都会在度假时开车。 因此你在下次更新时添加了规划步行路线的功能。 此后, 你又添加了规划公共交通路线的功能。
而这只是个开始。 不久后, 你又要为骑行者规划路线。 又过了一段时间, 你又要为游览城市中的所有景点规划路线。
尽管从商业角度来看, 这款应用非常成功, 但其技术部分却让你非常头疼: 每次添加新的路线规划算法后, 导游应用中主要类的体积就会增加一倍。 终于在某个时候, 你觉得自己没法继续维护这堆代码了。
无论是修复简单缺陷还是微调街道权重, 对某个算法进行任何修改都会影响整个类, 从而增加在已有正常运行代码中引入错误的风险。
此外, 团队合作将变得低效。 如果你在应用成功发布后招募了团队成员, 他们会抱怨在合并冲突的工作上花费了太多时间。 在实现新功能的过程中, 你的团队需要修改同一个巨大的类, 这样他们所编写的代码相互之间就可能会出现冲突。
- 方案、架构
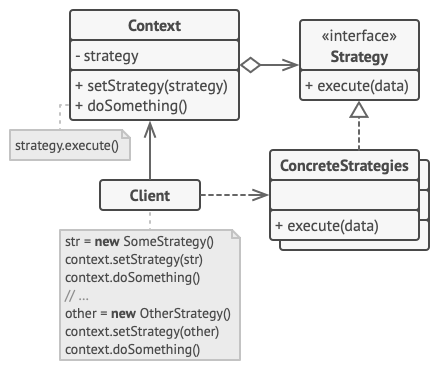
策略模式建议找出负责用许多不同方式完成特定任务的类, 然后将其中的算法抽取到一组被称为策略的独立类中。
名为上下文的原始类必须包含一个成员变量来存储对于每种策略的引用。 上下文并不执行任务, 而是将工作委派给已连接的策略对象。
上下文不负责选择符合任务需要的算法——客户端会将所需策略传递给上下文。 实际上, 上下文并不十分了解策略, 它会通过同样的通用接口与所有策略进行交互, 而该接口只需暴露一个方法来触发所选策略中封装的算法即可。
因此, 上下文可独立于具体策略。 这样你就可在不修改上下文代码或其他策略的情况下添加新算法或修改已有算法了。
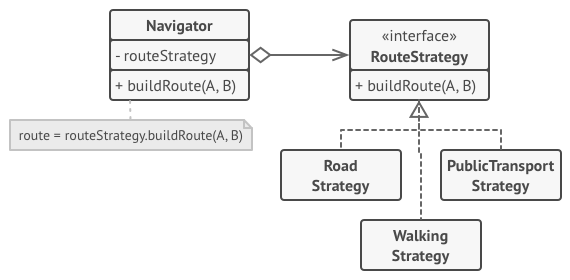
在导游应用中, 每个路线规划算法都可被抽取到只有一个 buildRoute生成路线方法的独立类中。 该方法接收起点和终点作为参数, 并返回路线中途点的集合。
即使传递给每个路径规划类的参数一模一样, 其所创建的路线也可能完全不同。 主要导游类的主要工作是在地图上渲染一系列中途点, 不会在意如何选择算法。 该类中还有一个用于切换当前路径规划策略的方法, 因此客户端 (例如用户界面中的按钮) 可用其他策略替换当前选择的路径规划行为。
在本例中, 上下文使用了多个策略来执行不同的计算操作。
// 策略接口声明了某个算法各个不同版本间所共有的操作。上下文会使用该接口来// 调用有具体策略定义的算法。interface Strategy is method execute(a, b)
// 具体策略会在遵循策略基础接口的情况下实现算法。该接口实现了它们在上下文// 中的互换性。class ConcreteStrategyAdd implements Strategy is method execute(a, b) is return a + b
class ConcreteStrategySubtract implements Strategy is method execute(a, b) is return a - b
class ConcreteStrategyMultiply implements Strategy is method execute(a, b) is return a * b
// 上下文定义了客户端关注的接口。class Context is // 上下文会维护指向某个策略对象的引用。上下文不知晓策略的具体类。上下 // 文必须通过策略接口来与所有策略进行交互。 private strategy: Strategy
// 上下文通常会通过构造函数来接收策略对象,同时还提供设置器以便在运行 // 时切换策略。 method setStrategy(Strategy strategy) is this.strategy = strategy
// 上下文会将一些工作委派给策略对象,而不是自行实现不同版本的算法。 method executeStrategy(int a, int b) is return strategy.execute(a, b)
// 客户端代码会选择具体策略并将其传递给上下文。客户端必须知晓策略之间的差// 异,才能做出正确的选择。class ExampleApplication is method main() is
创建上下文对象。
读取第一个数。 读取最后一个数。 从用户输入中读取期望进行的行为。
if (action == addition) then context.setStrategy(new ConcreteStrategyAdd())
if (action == subtraction) then context.setStrategy(new ConcreteStrategySubtract())
if (action == multiplication) then context.setStrategy(new ConcreteStrategyMultiply())
result = context.executeStrategy(First number, Second number)
打印结果。- 适用场景
当你想使用对象中各种不同的算法变体, 并希望能在运行时切换算法时, 可使用策略模式。
策略模式让你能够将对象关联至可以不同方式执行特定子任务的不同子对象, 从而以间接方式在运行时更改对象行为。
当你有许多仅在执行某些行为时略有不同的相似类时, 可使用策略模式。
策略模式让你能将不同行为抽取到一个独立类层次结构中, 并将原始类组合成同一个, 从而减少重复代码。
如果算法在上下文的逻辑中不是特别重要, 使用该模式能将类的业务逻辑与其算法实现细节隔离开来。
策略模式让你能将各种算法的代码、 内部数据和依赖关系与其他代码隔离开来。 不同客户端可通过一个简单接口执行算法, 并能在运行时进行切换。
当类中使用了复杂条件运算符以在同一算法的不同变体中切换时, 可使用该模式。
策略模式将所有继承自同样接口的算法抽取到独立类中, 因此不再需要条件语句。 原始对象并不实现所有算法的变体, 而是将执行工作委派给其中的一个独立算法对象。
- 优缺点
优点
- 你可以在运行时切换对象内的算法。
- 你可以将算法的实现和使用算法的代码隔离开来。
- 你可以使用组合来代替继承。
- 开闭原则。 你无需对上下文进行修改就能够引入新的策略。
缺点
- 如果你的算法极少发生改变, 那么没有任何理由引入新的类和接口。 使用该模式只会让程序过于复杂。
- 客户端必须知晓策略间的不同——它需要选择合适的策略。
- 许多现代编程语言支持函数类型功能, 允许你在一组匿名函数中实现不同版本的算法。 这样, 你使用这些函数的方式就和使用策略对象时完全相同, 无需借助额外的类和接口来保持代码简洁。
- 与其他模式的关系
桥接模式、 状态模式和策略模式 (在某种程度上包括适配器模式) 模式的接口非常相似。 实际上, 它们都基于组合模式——即将工作委派给其他对象, 不过也各自解决了不同的问题。 模式并不只是以特定方式组织代码的配方, 你还可以使用它们来和其他开发者讨论模式所解决的问题。
命令模式和策略看上去很像, 因为两者都能通过某些行为来参数化对象。 但是, 它们的意图有非常大的不同。
2.1 你可以使用命令来将任何操作转换为对象。 操作的参数将成为对象的成员变量。 你可以通过转换来延迟操作的执行、 将操作放入队列、 保存历史命令或者向远程服务发送命令等。
2.2 另一方面, 策略通常可用于描述完成某件事的不同方式, 让你能够在同一个上下文类中切换算法。
装饰模式可让你更改对象的外表, 策略则让你能够改变其本质。
模板方法模式基于继承机制: 它允许你通过扩展子类中的部分内容来改变部分算法。 策略基于组合机制: 你可以通过对相应行为提供不同的策略来改变对象的部分行为。 模板方法在类层次上运作, 因此它是静态的。 策略在对象层次上运作, 因此允许在运行时切换行为。
状态可被视为策略的扩展。 两者都基于组合机制: 它们都通过将部分工作委派给 “帮手” 对象来改变其在不同情景下的行为。 策略使得这些对象相互之间完全独立, 它们不知道其他对象的存在。 但状态模式没有限制具体状态之间的依赖, 且允许它们自行改变在不同情景下的状态。
3.9 模板方法模式
- 问题
假如你正在开发一款分析公司文档的数据挖掘程序。 用户需要向程序输入各种格式 (PDF、 DOC 或 CSV) 的文档, 程序则会试图从这些文件中抽取有意义的数据, 并以统一的格式将其返回给用户。
该程序的首个版本仅支持 DOC 文件。 在接下来的一个版本中, 程序能够支持 CSV 文件。 一个月后, 你 “教会” 了程序从 PDF 文件中抽取数据。
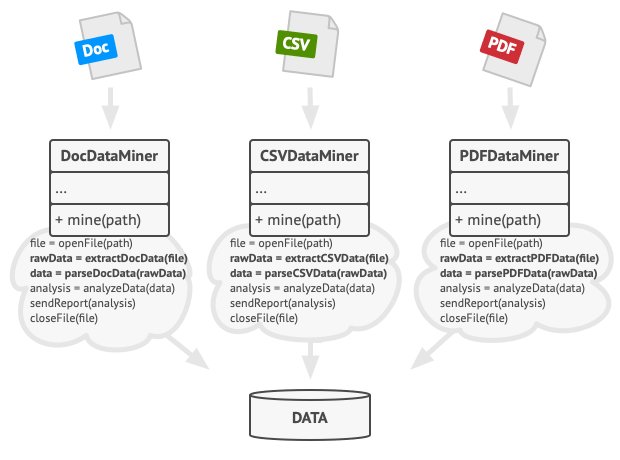
一段时间后, 你发现这三个类中包含许多相似代码。 尽管这些类处理不同数据格式的代码完全不同, 但数据处理和分析的代码却几乎完全一样。 如果能在保持算法结构完整的情况下去除重复代码, 这难道不是一件很棒的事情吗?
还有另一个与使用这些类的客户端代码相关的问题: 客户端代码中包含许多条件语句, 以根据不同的处理对象类型选择合适的处理过程。 如果所有处理数据的类都拥有相同的接口或基类, 那么你就可以去除客户端代码中的条件语句, 转而使用多态机制来在处理对象上调用函数。
- 方案、架构
模板方法模式建议将算法分解为一系列步骤, 然后将这些步骤改写为方法, 最后在 “模板方法” 中依次调用这些方法。 步骤可以是 抽象的, 也可以有一些默认的实现。 为了能够使用算法, 客户端需要自行提供子类并实现所有的抽象步骤。 如有必要还需重写一些步骤 (但这一步中不包括模板方法自身)。
让我们考虑如何在数据挖掘应用中实现上述方案。 我们可为图中的三个解析算法创建一个基类, 该类将定义调用了一系列不同文档处理步骤的模板方法。
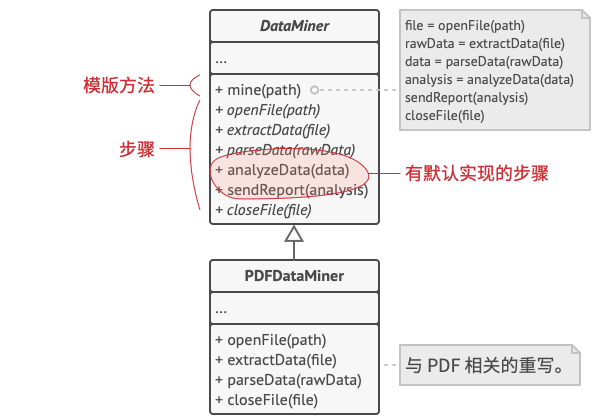
首先, 我们将所有步骤声明为 抽象类型, 强制要求子类自行实现这些方法。 在我们的例子中, 子类中已有所有必要的实现, 因此我们只需调整这些方法的签名, 使之与超类的方法匹配即可。
现在, 让我们看看如何去除重复代码。 对于不同的数据格式, 打开和关闭文件以及抽取和解析数据的代码都不同, 因此无需修改这些方法。 但分析原始数据和生成报告等其他步骤的实现方式非常相似, 因此可将其提取到基类中, 以让子类共享这些代码。
正如你所看到的那样, 我们有两种类型的步骤:
抽象步骤必须由各个子类来实现
可选步骤已有一些默认实现, 但仍可在需要时进行重写
还有另一种名为钩子的步骤。 钩子是内容为空的可选步骤。 即使不重写钩子, 模板方法也能工作。 钩子通常放置在算法重要步骤的前后, 为子类提供额外的算法扩展点。
本例中的模板方法模式为一款简单策略游戏中人工智能的不同分支提供 “框架”。
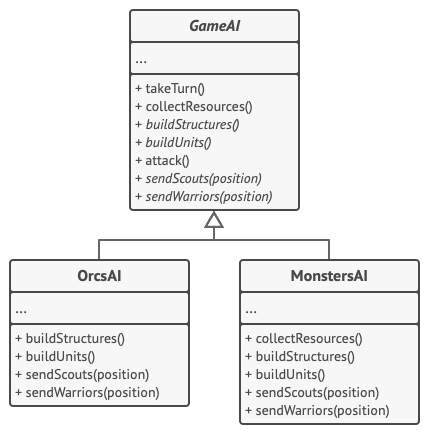
游戏中所有的种族都有几乎同类的单位和建筑。 因此你可以在不同的种族上复用相同的 AI 结构, 同时还需要具备重写一些细节的能力。 通过这种方式, 你可以重写半兽人的 AI 使其更富攻击性, 也可以让人类侧重防守, 还可以禁止怪物建造建筑。 在游戏中新增种族需要创建新的 AI 子类, 还需要重写 AI 基类中所声明的默认方法。
// 抽象类定义了一个模板方法,其中通常会包含某个由抽象原语操作调用组成的算// 法框架。具体子类会实现这些操作,但是不会对模板方法做出修改。class GameAI is // 模板方法定义了某个算法的框架。 method turn() is collectResources() buildStructures() buildUnits() attack()
// 某些步骤可在基类中直接实现。 method collectResources() is foreach (s in this.builtStructures) do s.collect()
// 某些可定义为抽象类型。 abstract method buildStructures() abstract method buildUnits()
// 一个类可包含多个模板方法。 method attack() is enemy = closestEnemy() if (enemy == null) sendScouts(map.center) else sendWarriors(enemy.position)
abstract method sendScouts(position) abstract method sendWarriors(position)
// 具体类必须实现基类中的所有抽象操作,但是它们不能重写模板方法自身。class OrcsAI extends GameAI is method buildStructures() is if (there are some resources) then // 建造农场,接着是谷仓,然后是要塞。
method buildUnits() is if (there are plenty of resources) then if (there are no scouts) // 建造苦工,将其加入侦查编组。 else // 建造兽族步兵,将其加入战士编组。
// ...
method sendScouts(position) is if (scouts.length > 0) then // 将侦查编组送到指定位置。
method sendWarriors(position) is if (warriors.length > 5) then // 将战斗编组送到指定位置。
// 子类可以重写部分默认的操作。class MonstersAI extends GameAI is method collectResources() is // 怪物不会采集资源。
method buildStructures() is // 怪物不会建造建筑。
method buildUnits() is // 怪物不会建造单位。- 适用场景
当你只希望客户端扩展某个特定算法步骤, 而不是整个算法或其结构时, 可使用模板方法模式。
模板方法将整个算法转换为一系列独立的步骤, 以便子类能对其进行扩展, 同时还可让超类中所定义的结构保持完整。
当多个类的算法除一些细微不同之外几乎完全一样时, 你可使用该模式。 但其后果就是, 只要算法发生变化, 你就可能需要修改所有的类。
在将算法转换为模板方法时, 你可将相似的实现步骤提取到超类中以去除重复代码。 子类间各不同的代码可继续保留在子类中。
- 优缺点
优点
- 你可仅允许客户端重写一个大型算法中的特定部分, 使得算法其他部分修改对其所造成的影响减小。
- 你可将重复代码提取到一个超类中。
缺点
- 部分客户端可能会受到算法框架的限制。
- 通过子类抑制默认步骤实现可能会导致违反里氏替换原则。
- 模板方法中的步骤越多, 其维护工作就可能会越困难。
- 与其他模式的关系
工厂方法模式是模板方法模式的一种特殊形式。 同时, 工厂方法可以作为一个大型模板方法中的一个步骤。
模板方法基于继承机制: 它允许你通过扩展子类中的部分内容来改变部分算法。 策略模式基于组合机制: 你可以通过对相应行为提供不同的策略来改变对象的部分行为。 模板方法在类层次上运作, 因此它是静态的。 策略在对象层次上运作, 因此允许在运行时切换行为。
3.10 访问者模式
- 问题
假如你的团队开发了一款能够使用巨型图像中地理信息的应用程序。 图像中的每个节点既能代表复杂实体 (例如一座城市), 也能代表更精细的对象 (例如工业区和旅游景点等)。 如果节点代表的真实对象之间存在公路, 那么这些节点就会相互连接。 在程序内部, 每个节点的类型都由其所属的类来表示, 每个特定的节点则是一个对象。
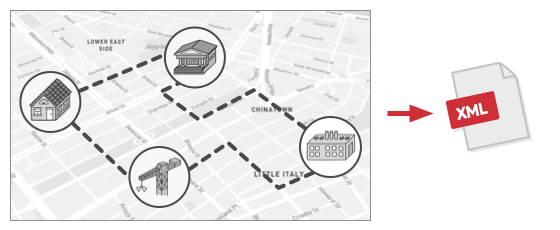
一段时间后, 你接到了实现将图像导出到 XML 文件中的任务。 这些工作最初看上去非常简单。 你计划为每个节点类添加导出函数, 然后递归执行图像中每个节点的导出函数。 解决方案简单且优雅: 使用多态机制可以让导出方法的调用代码不会和具体的节点类相耦合。
但你不太走运, 系统架构师拒绝批准对已有节点类进行修改。 他认为这些代码已经是产品了, 不想冒险对其进行修改, 因为修改可能会引入潜在的缺陷。
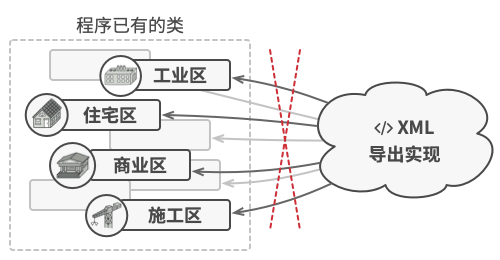
此外, 他还质疑在节点类中包含导出 XML 文件的代码是否有意义。 这些类的主要工作是处理地理数据。 导出 XML 文件的代码放在这里并不合适。
还有另一个原因, 那就是在此项任务完成后, 营销部门很有可能会要求程序提供导出其他类型文件的功能, 或者提出其他奇怪的要求。 这样你很可能会被迫再次修改这些重要但脆弱的类。
- 方案、架构
访问者模式建议将新行为放入一个名为访问者的独立类中, 而不是试图将其整合到已有类中。 现在, 需要执行操作的原始对象将作为参数被传递给访问者中的方法, 让方法能访问对象所包含的一切必要数据。
如果现在该操作能在不同类的对象上执行会怎么样呢? 比如在我们的示例中, 各节点类导出 XML 文件的实际实现很可能会稍有不同。 因此, 访问者类可以定义一组 (而不是一个) 方法, 且每个方法可接收不同类型的参数, 如下所示:
class ExportVisitor implements Visitor is method doForCity(City c) { ... } method doForIndustry(Industry f) { ... } method doForSightSeeing(SightSeeing ss) { ... } // ...但我们究竟应该如何调用这些方法 (尤其是在处理整个图像方面) 呢? 这些方法的签名各不相同, 因此我们不能使用多态机制。 为了可以挑选出能够处理特定对象的访问者方法, 我们需要对它的类进行检查。 这是不是听上去像个噩梦呢?
foreach (Node node in graph) if (node instanceof City) exportVisitor.doForCity((City) node) if (node instanceof Industry) exportVisitor.doForIndustry((Industry) node) // ...}你可能会问, 我们为什么不使用方法重载呢? 就是使用相同的方法名称, 但它们的参数不同。 不幸的是, 即使我们的编程语言 (例如 Java 和 C#) 支持重载也不行。 由于我们无法提前知晓节点对象所属的类, 所以重载机制无法执行正确的方法。 方法会将 节点基类作为输入参数的默认类型。
但是, 访问者模式可以解决这个问题。 它使用了一种名为双分派的技巧, 不使用累赘的条件语句也可下执行正确的方法。 与其让客户端来选择调用正确版本的方法, 不如将选择权委派给作为参数传递给访问者的对象。 由于该对象知晓其自身的类, 因此能更自然地在访问者中选出正确的方法。 它们会 “接收” 一个访问者并告诉其应执行的访问者方法。
// 客户端代码foreach (Node node in graph) node.accept(exportVisitor)
// 城市class City is method accept(Visitor v) is v.doForCity(this) // ...
// 工业区class Industry is method accept(Visitor v) is v.doForIndustry(this) // ...我承认最终还是修改了节点类, 但毕竟改动很小, 且使得我们能够在后续进一步添加行为时无需再次修改代码。
现在, 如果我们抽取出所有访问者的通用接口, 所有已有的节点都能与我们在程序中引入的任何访问者交互。 如果需要引入与节点相关的某个行为, 你只需要实现一个新的访问者类即可。
在本例中, 访问者模式为几何图像层次结构添加了对于 XML 文件导出功能的支持。
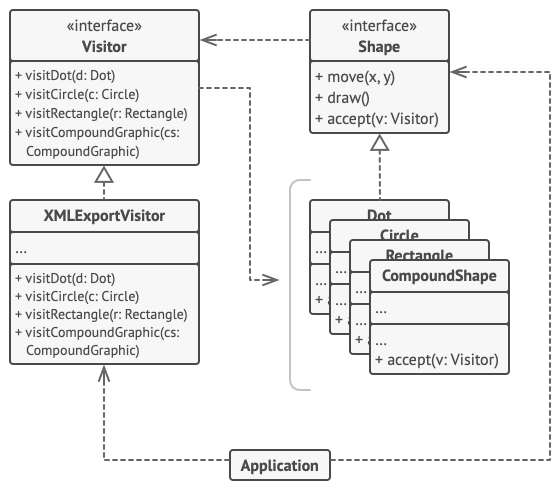
- 适用场景
如果你需要对一个复杂对象结构 (例如对象树) 中的所有元素执行某些操作, 可使用访问者模式。
访问者模式通过在访问者对象中为多个目标类提供相同操作的变体, 让你能在属于不同类的一组对象上执行同一操作。
可使用访问者模式来清理辅助行为的业务逻辑。
该模式会将所有非主要的行为抽取到一组访问者类中, 使得程序的主要类能更专注于主要的工作。
当某个行为仅在类层次结构中的一些类中有意义, 而在其他类中没有意义时, 可使用该模式。
你可将该行为抽取到单独的访问者类中, 只需实现接收相关类的对象作为参数的访问者方法并将其他方法留空即可。
- 优缺点
优点
- 开闭原则。 你可以引入在不同类对象上执行的新行为, 且无需对这些类做出修改。
- 单一职责原则。 可将同一行为的不同版本移到同一个类中。
- 访问者对象可以在与各种对象交互时收集一些有用的信息。 当你想要遍历一些复杂的对象结构 (例如对象树), 并在结构中的每个对象上应用访问者时, 这些信息可能会有所帮助。
缺点
- 每次在元素层次结构中添加或移除一个类时, 你都要更新所有的访问者。
- 在访问者同某个元素进行交互时, 它们可能没有访问元素私有成员变量和方法的必要权限。
- 与其他模式的关系
你可以将访问者模式视为命令模式的加强版本, 其对象可对不同类的多种对象执行操作。
你可以使用访问者对整个组合模式树执行操作。
可以同时使用访问者和迭代器模式来遍历复杂数据结构, 并对其中的元素执行所需操作, 即使这些元素所属的类完全不同。
